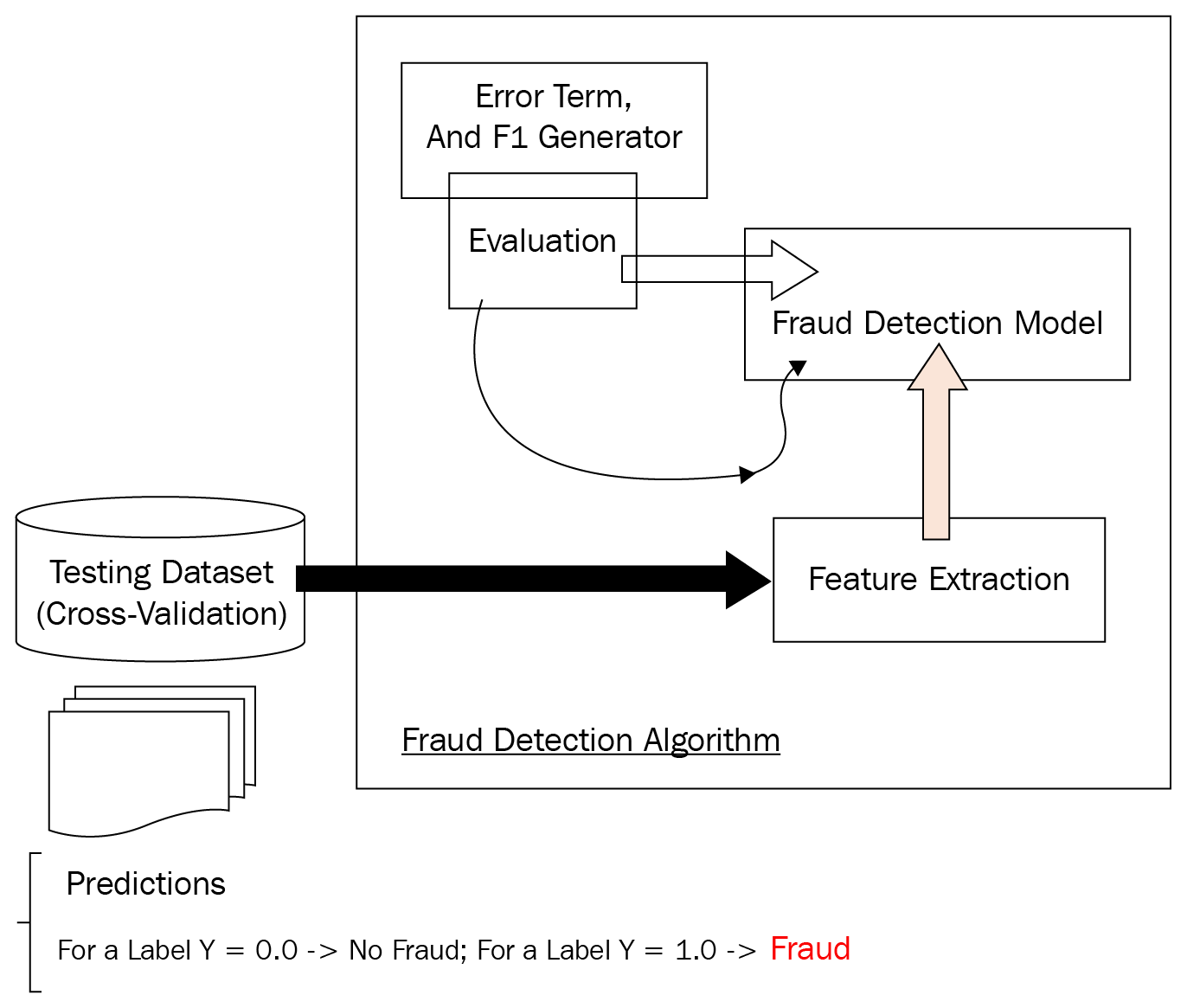
The following diagram illustrates the high-level architecture for our fraud detection pipeline:
High-level architecture for the fraud detection pipeline
The following is a quick overview of the fraud detection process:
- First, we compute statistics on the training set, which serves as a cross-validation dataset. We are interested in the mean and standard deviation from the statistical numbers.
- Next, we want to compute the net probability density function (PDF) for each sample in our cross-validation set.
- We derive the net probability density as a product of the individual probability densities.
- Inside the algorithm, ...