2.7
機械学習モデル(
Part
Ⅱ)
53
print('Training Log Loss: ', loglossTraining)
print('CV Log Loss: ', loglossCV)
loglossXGBoostGradientBoosting = \
log_loss(y_train, predictionsBasedOnKFolds.loc[:,'prediction'])
print('XGBoost Gradient Boosting Log Loss: ', loglossXGBoostGradientBoosting)
2.7.2.3
結果の評価
下に示すように、訓練セット全体に対する(交差検証予測を用いた)対数損失は、ランダムフォレス
トの場合の
1/5
、ロジスティック回帰の場合の
1/15
になっている。これは素晴らしい改善だ。
XGBoost Gradient Boosting Log Loss: 0.0029566906288156715
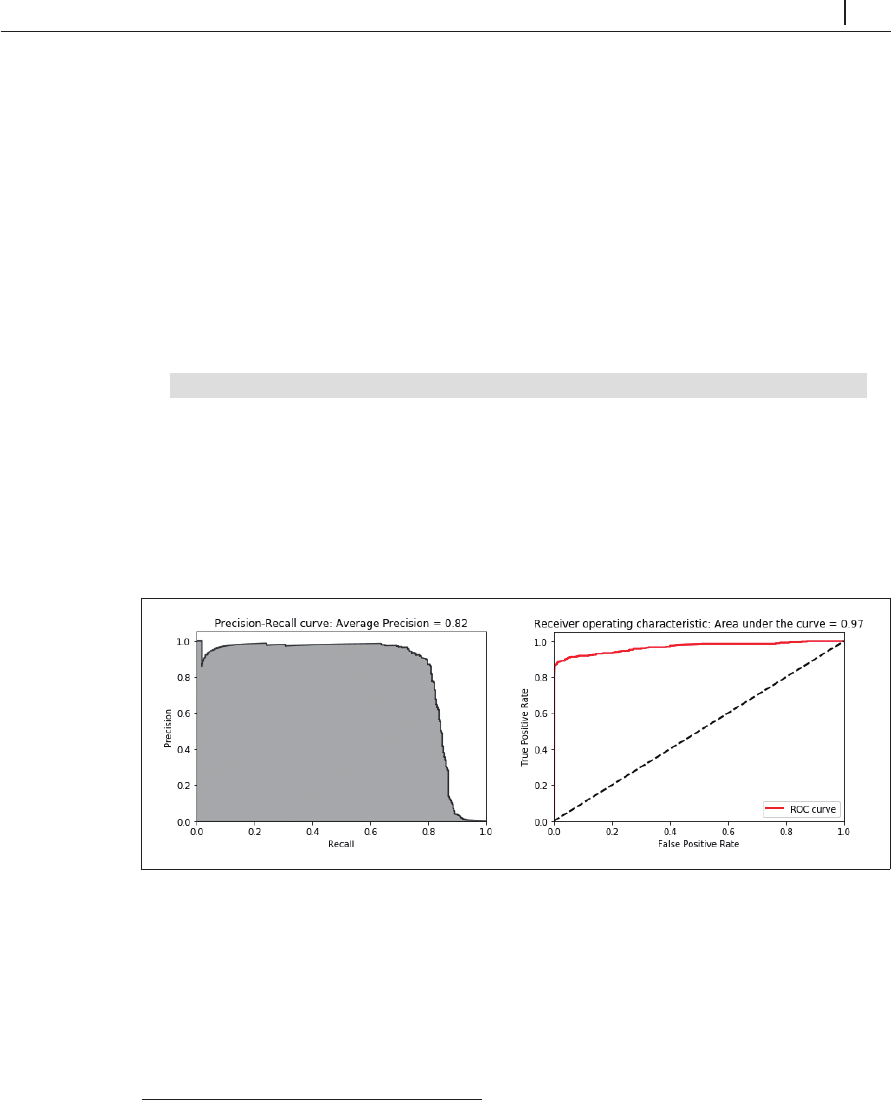
図 2 - 7( 左 )に示したように、平均適合率は
0.82
で、ランダムフォレストの
0.79
よりも少し良く、ロジ
スティック回帰の
0.73
よりはかなり良い。
図 2 - 7( 右 )に示すように、
auROC
曲線は
0.97
で、ロジスティック回帰の場合と同じで、ランダムフォ
レストの
0.93
よりは少し良い。これまでのところ、対数損失、適合率
-
再現率曲線、
auROC
のすべて
の面で、
3
つのモデルのうちでは勾配ブースティングが一番良い。






