5.4
階層クラスタリング
127
99, 199, 299, 399, 499, 599, 699, 783], \
columns=['overallAccuracy'])
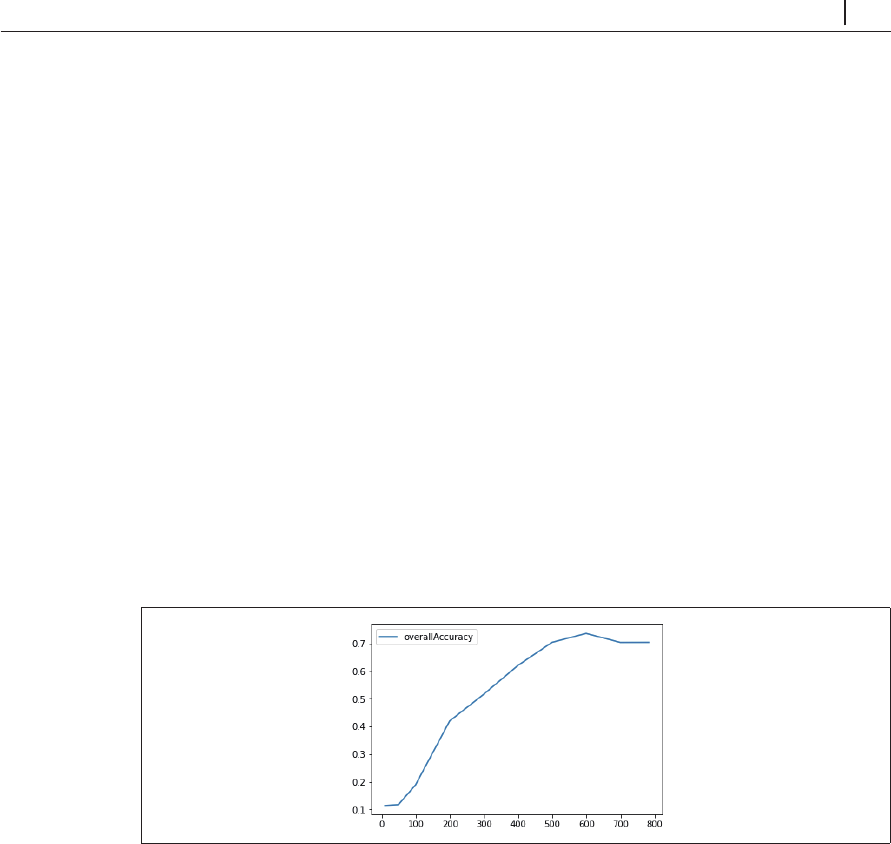
for cutoffNumber in [9, 49, 99, 199, 299, 399, 499, 599, 699, 783]:
kmeans = KMeans(n_clusters=n_clusters, n_init=n_init, \
max_iter=max_iter, tol=tol, random_state=random_state, \
n_jobs=n_jobs)
cutoff = cutoffNumber
kmeans.fit(X_train.loc[:,0:cutoff])
kMeans_inertia.loc[cutoff] = kmeans.inertia_
X_train_kmeansClustered = kmeans.predict(X_train.loc[:,0:cutoff])
X_train_kmeansClustered = pd.DataFrame(data=X_train_kmeansClustered, \
index=X_train.index, columns=['cluster'])
countByCluster_kMeans, countByLabel_kMeans, countMostFreq_kMeans, \
accuracyDF_kMeans, ...






