3.11 Detection of Outliers
We noted above that a measure of central location such as the mean is affected by each observation in a data set and thus by extreme values. Extreme values may or may not be outliers (atypical or unusually small or large data values). For instance, given the data set X: 1, 3, 6, 7, 8, 10, it is obvious that 1 and 10 are extreme values for this data set, but they are not outliers. If, instead, we had X: 1, 3, 6, 7, 8, 42, then, clearly, 42 is an extreme value that would also qualify as an outlier.
There are two ways to check a data set for outliers:
1. We can apply the empirical rule—for a data set that is normally distributed (or approximately so, but certainly symmetrical), we can use
Z-scores to identify outliers: an observation
Xi is deemed an outlier if it is
Z-score
Zi lies below –2.24 or above 2.24. Here ± 2.24 are the
cut-off points or
fences that leave us with only 2.5% of the data in each tail of the distribution. Both of these cases can be subsumed under the inequality
(3.19) 
While
Equation (3.19) is commonly utilized to detect outliers, its usage ignores a rather acute problem—the values of both
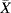
and
s are themselves affected by outliers. Why should we use a device for detecting outliers that itself is impacted by outliers? Since the median ...






