The following section explains how the images are loaded and read into a Jupyter notebook. Take a look at these steps:
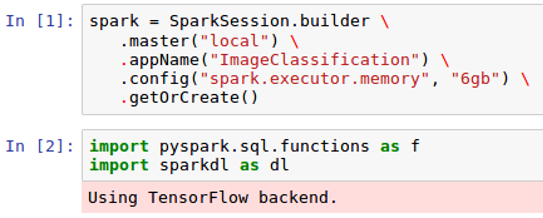
- We always begin a Spark project by initiating a Spark session to set the application name as well as to set the Spark executor memory.
- We import both pyspark.sql.functions and sparkdl to help build dataframes based on encoded images. When sparkdl is imported, we see that it is using TensorFlow in the backend, as seen in the following screenshot:
- The dataframes are created using sparkdl with three columns: filepath, image, and label. Sparkdl is used to import each image and encode it by color and shape. Additionally, ...