This section will walk through our design process for joining tables together as well as which final columns will be kept:
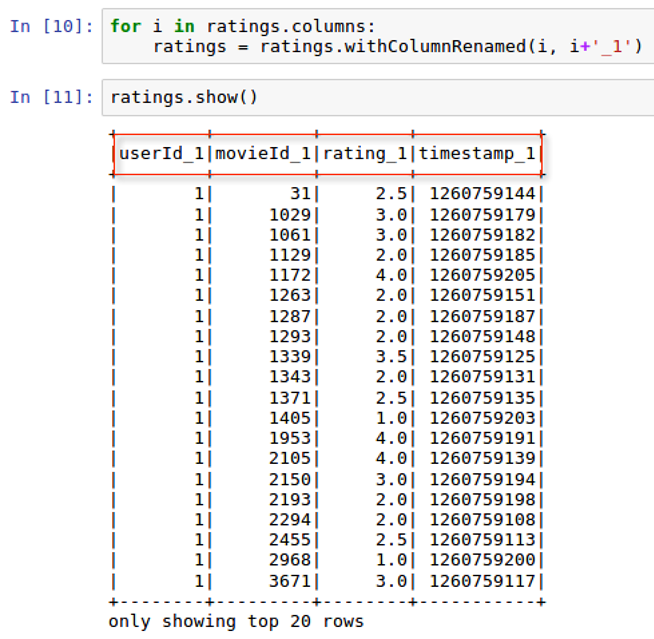
- As was mentioned in the previous section, the ratings dataframe will serve as our fact table, since it contains all the main transactions of ratings for each user over time. The columns in ratings will be used in each subsequent join with the other three tables, and to maintain a uniqueness of the columns, we will attach a _1 to the end of each column name, as seen in the following screenshot:
- We can now join the three lookup tables to the ratings table. The first two joins to ratings are inner joins, ...