Content preview from Apache Spark Deep Learning Cookbook
Consider the following:
- In our case, we notice the build_vocab function identifies 23,960 different word types from a list of 1,110,288 words. However, this number will vary for different text corpora.
- Each word is represented by a 300-dimensional vector since we have declared the dimensionality to be 300. Increasing this number increases the training time of the model but also makes sure the model generalizes easily to new data.
- The downsampling rate of 1e
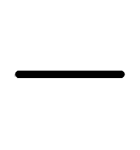 3 is found to be a good rate. This is specified to let the model know when to downsample frequently occurring words, as they are not of much importance when it comes to analysis. ...
3 is found to be a good rate. This is specified to let the model know when to downsample frequently occurring words, as they are not of much importance when it comes to analysis. ...
Become an O’Reilly member and get unlimited access to this title plus top books and audiobooks from O’Reilly and nearly 200 top publishers, thousands of courses curated by job role, 150+ live events each month,
and much more.
Read now
Unlock full access
More than 5,000 organizations count on O’Reilly
 O’Reilly covers everything we've got, with content to help us build a world-class technology community, upgrade the capabilities and competencies of our teams, and improve overall team performance as well as their engagement.
O’Reilly covers everything we've got, with content to help us build a world-class technology community, upgrade the capabilities and competencies of our teams, and improve overall team performance as well as their engagement.Julian F.
I wanted to learn C and C++, but it didn't click for me until I picked up an O'Reilly book. When I went on the O’Reilly platform, I was astonished to find all the books there, plus live events and sandboxes so you could play around with the technology.Addison B.
I’ve been on the O’Reilly platform for more than eight years. I use a couple of learning platforms, but I'm on O'Reilly more than anybody else. When you're there, you start learning. I'm never disappointed.Amir M.
I'm always learning. So when I got on to O'Reilly, I was like a kid in a candy store. There are playlists. There are answers. There's on-demand training. It's worth its weight in gold, in terms of what it allows me to do.Mark W.
Publisher Resources
ISBN: 9781788474221 





