FURTHER CONSIDERATIONS
Bad Data
The presence of bad data can completely distort regression calculations. When least-squares methods are employed, a single outlier can influence the entire line to pass closely to the outlier.
Consider the effect on the regression line in Figure 11.5 if we were to eliminate the systolic blood pressure reading of 220 for a 47-year old. The slope increases and the intercept decreases.
FIGURE 11.5. Effect on the Model of Eliminating an Outlying Observation.
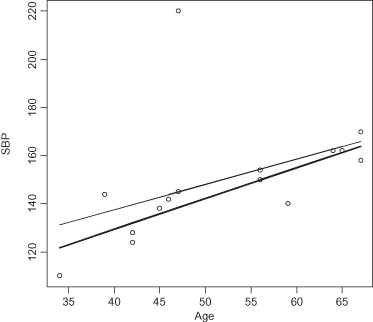
Although a number of methods exist for detecting the most influential observations (see, for example, Mosteller and Tukey, 1977), influential does not automatically mean that the data point is in error. Measures of influence encourage review of data for exclusion. Statistics do not exclude data; analysts do. And they only exclude data when presented with firm evidence that the data are in error.
The problem of bad data is particularly acute in two instances:
The Washington State Department of Social and Health Services extrapolates its audit results on the basis of a regression of over- and undercharges against the dollar amount of the claim. As the frequency of errors depends on the amount of paperwork ...
Get Common Errors in Statistics (and How to Avoid Them), 4th Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

