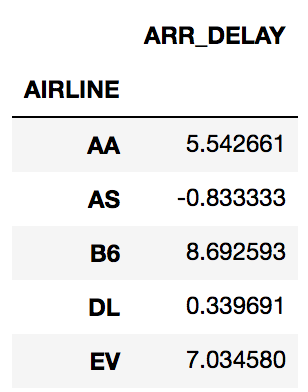
- Read in the flights dataset, and define the grouping columns (AIRLINE), aggregating columns (ARR_DELAY), and aggregating functions (mean):
>>> flights = pd.read_csv('data/flights.csv')>>> flights.head()
- Place the grouping column in the groupby method and then call the agg method with a dictionary pairing the aggregating column with its aggregating function:
>>> flights.groupby('AIRLINE').agg({'ARR_DELAY':'mean'}).head()
- Alternatively, you may place the aggregating column in the indexing operator and then pass the aggregating ...