Once you realize that Majordomo is a âreliableâ message broker, you might be tempted to add some spinning rust (that is, ferrous-based hard disk platters). After all, this works for all the enterprise messaging systems. Itâs such a tempting idea that itâs a little sad to have to be negative toward it. But brutal cynicism is one of my specialties. So, some reasons you donât want rust-based brokers sitting in the center of your architecture are:
As youâve seen, the Lazy Pirate client performs surprisingly well. It works across a whole range of architectures, from direct client-to-server to distributed queue proxies. It does tend to assume that workers are stateless and idempotent, but we can work around that limitation without resorting to rust.
Rust brings a whole set of problems, from slow performance to additional pieces that you have to manage, repair, and handle 6 a.m. panics from, as they inevitably break at the start of daily operations. The beauty of the Pirate patterns in general is their simplicity. They wonât crash. And if youâre still worried about the hardware, you can move to a peer-to-peer pattern that has no broker at all (Iâll explain that later in this chapter).
Having said this, however, there is one sane use case for rust-based reliability, which is an asynchronous disconnected network. It solves a major problem with Pirate, namely that a client has to wait for an answer in real time. If clients and workers are only sporadically connected (think of email as an analogy), we canât use a stateless network between clients and workers. We have to put state in the middle.
So, hereâs the Titanic pattern (Figure 4-5), in which we write messages to disk to ensure they never get lost, no matter how sporadically clients and workers are connected. As we did for service discovery, weâre going to layer Titanic on top of MDP rather than extend it. Itâs wonderfully lazy because it means we can implement our fire-and-forget reliability in a specialized worker, rather than in the broker. This is excellent for several reasons:
It is much easier because we divide and conquer: the broker handles message routing and the worker handles reliability.
It lets us mix brokers written in one language with workers written in another.
It lets us evolve the fire-and-forget technology independently.
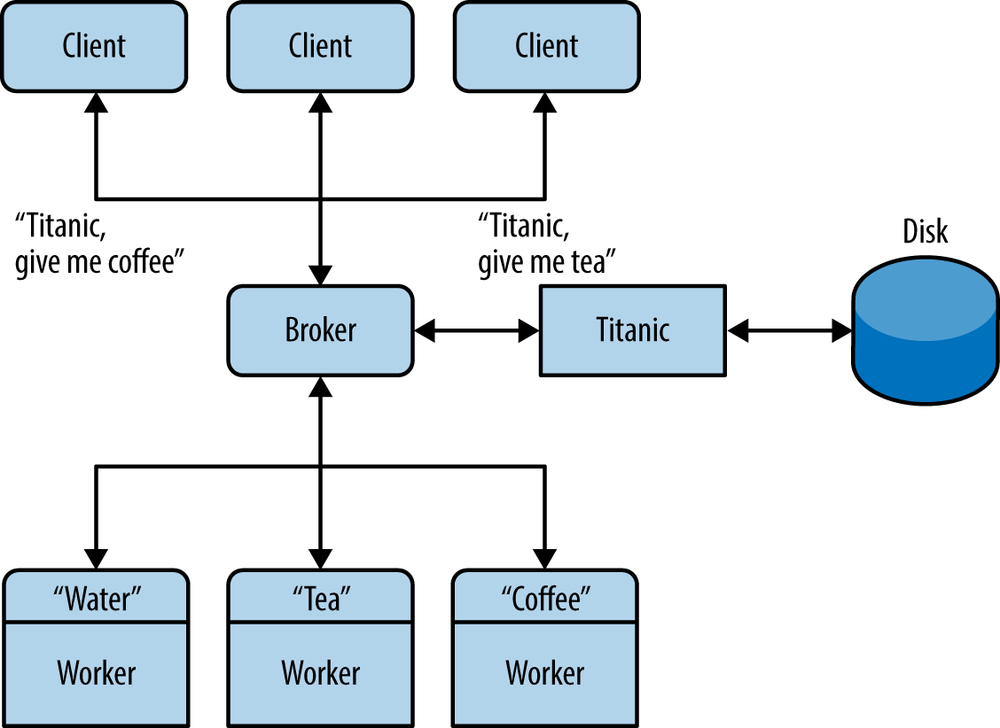
The only downside is that thereâs an extra network hop between broker and hard disk. The benefits are easily worth it.
There are many ways to make a persistent request-reply architecture. Weâll aim for one that is simple and painless. The simplest design I could come up with, after playing with this for a few hours, was a âproxy service.â That is, Titanic doesnât affect workers at all. If a client wants a reply immediately, it talks directly to a service and hopes the service is available. If a client is happy to wait a while, it talks to Titanic instead and asks, âHey, buddy, would you take care of this for me while I go buy my groceries?â
Titanic is thus both a worker and a client. The dialog between the client and Titanic goes along these lines:
Client: âPlease accept this request for me.â Titanic: âOK, done.â
Client: âDo you have a reply for me?â Titanic: âYes, here it is.â (Or, âNo, not yetâ.)
Client: âOK, you can wipe that request now, Iâm happy.â Titanic: âOK, done.â
Whereas the dialog between Titanic and the broker and worker goes like this:
Titanic: âHey, Broker, is there a coffee service?â
Broker: âUm, yeah, seems like there is.â
Titanic: âHey, coffee service, please handle this for me.â
Coffee: âSure, here you are.â
Titanic: âSweeeeet!â
You can work through these and the possible failure scenarios. If a worker crashes while processing a request, Titanic retries, indefinitely. If a reply gets lost somewhere, Titanic will retry. If the request gets processed but the client doesnât get the reply, it will ask again. If Titanic crashes while processing a request or a reply, the client will try again. As long as requests are fully committed to safe storage, work canât get lost.
The handshaking is pedantic, but can be pipelined; i.e., clients can use the asynchronous Majordomo pattern to do a lot of work and then get the responses later.
We need some way for a client to request its replies. Weâll have many clients asking for the same services, and clients may disappear and reappear with different identities. Here is a simple, reasonably secure solution:
Every request generates a universally unique ID (UUID), which Titanic returns to the client after it has queued the request.
When a client asks for a reply, it must specify the UUID for the original request.
In a realistic case, the client would want to store its request UUIDs safely, such as in a local database.
Before we jump off and write yet another formal specification (fun, fun!), letâs consider how the client talks to Titanic. One way is to use a single service and send it three different request types. Another way, which seems simpler, is to use three services:
titanic.requestStores a request message, and return a UUID for the request.
titanic.replyFetches a reply, if available, for a given request UUID.
titanic.closeConfirms that a reply has been stored and processed.
Weâll just make a multithreaded worker, which, as weâve seen from our multithreading experience with ÃMQ, is trivial. However, letâs first sketch what Titanic would look like in terms of ÃMQ messages and frames. This gives us the Titanic Service Protocol (TSP).
Using TSP is clearly more work for client applications than accessing a service directly via MDP. The shortest robust âechoâ client example is presented in Example 4-53.
Example 4-53. Titanic client example (ticlient.c)
//// Titanic client example// Implements client side of http://rfc.zeromq.org/spec:9// Lets us build this source without creating a library#include "mdcliapi.c"// Calls a TSP service// Returns response if successful (status code 200 OK), else NULL//staticzmsg_t*s_service_call(mdcli_t*session,char*service,zmsg_t**request_p){zmsg_t*reply=mdcli_send(session,service,request_p);if(reply){zframe_t*status=zmsg_pop(reply);if(zframe_streq(status,"200")){zframe_destroy(&status);returnreply;}elseif(zframe_streq(status,"400")){printf("E: client fatal error, aborting\n");exit(EXIT_FAILURE);}elseif(zframe_streq(status,"500")){printf("E: server fatal error, aborting\n");exit(EXIT_FAILURE);}}elseexit(EXIT_SUCCESS);// Interrupted or failedzmsg_destroy(&reply);returnNULL;// Didn't succeed; don't care why not}
The main task (Example 4-54) tests our service call by sending an echo request.
Example 4-54. Titanic client example (ticlient.c): main task
intmain(intargc,char*argv[]){intverbose=(argc>1&&streq(argv[1],"-v"));mdcli_t*session=mdcli_new("tcp://localhost:5555",verbose);// 1. Send 'echo' request to Titaniczmsg_t*request=zmsg_new();zmsg_addstr(request,"echo");zmsg_addstr(request,"Hello world");zmsg_t*reply=s_service_call(session,"titanic.request",&request);zframe_t*uuid=NULL;if(reply){uuid=zmsg_pop(reply);zmsg_destroy(&reply);zframe_print(uuid,"I: request UUID ");}// 2. Wait until we get a replywhile(!zctx_interrupted){zclock_sleep(100);request=zmsg_new();zmsg_add(request,zframe_dup(uuid));zmsg_t*reply=s_service_call(session,"titanic.reply",&request);if(reply){char*reply_string=zframe_strdup(zmsg_last(reply));printf("Reply: %s\n",reply_string);free(reply_string);zmsg_destroy(&reply);// 3. Close requestrequest=zmsg_new();zmsg_add(request,zframe_dup(uuid));reply=s_service_call(session,"titanic.close",&request);zmsg_destroy(&reply);break;}else{printf("I: no reply yet, trying again...\n");zclock_sleep(5000);// Try again in 5 seconds}}zframe_destroy(&uuid);mdcli_destroy(&session);return0;}
Of course, this can be, and should be, wrapped up in some kind of framework or API. Itâs not healthy to ask average application developers to learn the full details of messaging: it hurts their brains, costs time, and offers too many ways to introduce buggy complexity. Additionally, it makes it hard to add intelligence.
For example, this client blocks on each request, whereas in a real application weâd want to be doing useful work while tasks are executed. It requires some nontrivial plumbing to build a background thread and talk to that cleanly. This is the kind of thing you want to wrap in a nice simple API that the average developer cannot misuse. Itâs the same approach that we used for Majordomo.
The Titanic implementation is shown in Example 4-55 through 4-60. This server handles the three services using three threads, as proposed. It does full persistence to disk using the most brutal approach possible: one file per message. Itâs so simple, itâs scary. The only complex part is that it keeps a separate queue of all requests in order to avoid reading the directory over and over.
Example 4-55. Titanic broker example (titanic.c)
//// Titanic service//// Implements server side of http://rfc.zeromq.org/spec:9// Lets us build this source without creating a library#include "mdwrkapi.c"#include "mdcliapi.c"#include "zfile.h"#include <uuid/uuid.h>// Return a new UUID as a printable character string// Caller must free returned string when finished with itstaticchar*s_generate_uuid(void){charhex_char[]="0123456789ABCDEF";char*uuidstr=zmalloc(sizeof(uuid_t)*2+1);uuid_tuuid;uuid_generate(uuid);intbyte_nbr;for(byte_nbr=0;byte_nbr<sizeof(uuid_t);byte_nbr++){uuidstr[byte_nbr*2+0]=hex_char[uuid[byte_nbr]>>4];uuidstr[byte_nbr*2+1]=hex_char[uuid[byte_nbr]&15];}returnuuidstr;}// Returns freshly allocated request filename for given UUID#define TITANIC_DIR ".titanic"staticchar*s_request_filename(char*uuid){char*filename=malloc(256);snprintf(filename,256,TITANIC_DIR"/%s.req",uuid);returnfilename;}// Returns freshly allocated reply filename for given UUIDstaticchar*s_reply_filename(char*uuid){char*filename=malloc(256);snprintf(filename,256,TITANIC_DIR"/%s.rep",uuid);returnfilename;}
The titanic.request task (Example 4-56) waits for requests to this service. It writes
each request to disk and returns a UUID to the client. The client picks up
the reply asynchronously using the titanic.reply
service.
Example 4-56. Titanic broker example (titanic.c): Titanic request service
staticvoidtitanic_request(void*args,zctx_t*ctx,void*pipe){mdwrk_t*worker=mdwrk_new("tcp://localhost:5555","titanic.request",0);zmsg_t*reply=NULL;while(true){// Send reply if it's not null// And then get next request from brokerzmsg_t*request=mdwrk_recv(worker,&reply);if(!request)break;// Interrupted, exit// Ensure message directory existszfile_mkdir(TITANIC_DIR);// Generate UUID and save message to diskchar*uuid=s_generate_uuid();char*filename=s_request_filename(uuid);FILE*file=fopen(filename,"w");assert(file);zmsg_save(request,file);fclose(file);free(filename);zmsg_destroy(&request);// Send UUID through to message queuereply=zmsg_new();zmsg_addstr(reply,uuid);zmsg_send(&reply,pipe);// Now send UUID back to client// Done by the mdwrk_recv() at the top of the loopreply=zmsg_new();zmsg_addstr(reply,"200");zmsg_addstr(reply,uuid);free(uuid);}mdwrk_destroy(&worker);}
The titanic.reply task, shown in Example 4-57, checks if thereâs a reply for the specified
request (by UUID), and returns a 200 (OK), 300 (Pending), or 400 (Unknown)
accordingly.
Example 4-57. Titanic broker example (titanic.c): Titanic reply service
staticvoid*titanic_reply(void*context){mdwrk_t*worker=mdwrk_new("tcp://localhost:5555","titanic.reply",0);zmsg_t*reply=NULL;while(true){zmsg_t*request=mdwrk_recv(worker,&reply);if(!request)break;// Interrupted, exitchar*uuid=zmsg_popstr(request);char*req_filename=s_request_filename(uuid);char*rep_filename=s_reply_filename(uuid);if(zfile_exists(rep_filename)){FILE*file=fopen(rep_filename,"r");assert(file);reply=zmsg_load(NULL,file);zmsg_pushstr(reply,"200"):// OKfclose(file);}else{reply=zmsg_new();if(zfile_exists(req_filename))zmsg_pushstr(reply,"300");// Pendingelsezmsg_pushstr(reply,"400");// Unknown}zmsg_destroy(&request);free(uuid);free(req_filename);free(rep_filename);}mdwrk_destroy(&worker);return0;}
The titanic.close task, shown in Example 4-58, removes any waiting replies for the request
(specified by UUID). Itâs idempotent, so it is safe to call it more than
once in a row.
Example 4-58. Titanic broker example (titanic.c): Titanic close task
staticvoid*titanic_close(void*context){mdwrk_t*worker=mdwrk_new("tcp://localhost:5555","titanic.close",0);zmsg_t*reply=NULL;while(true){zmsg_t*request=mdwrk_recv(worker,&reply);if(!request)break;// Interrupted, exitchar*uuid=zmsg_popstr(request);char*req_filename=s_request_filename(uuid);char*rep_filename=s_reply_filename(uuid);zfile_delete(req_filename);zfile_delete(rep_filename);free(uuid);free(req_filename);free(rep_filename);zmsg_destroy(&request);reply=zmsg_new();zmsg_addstr(reply,"200");}mdwrk_destroy(&worker);return0;}
Example 4-59 shows the main thread for the Titanic
worker. It starts three child threads, for the request, reply, and close
services. It then dispatches requests to workers using a simple
brute-force disk queue. It receives request UUIDs from the
titanic.request service, saves these to a disk file,
and then throws each request at MDP workers until it gets a
response.
Example 4-59. Titanic broker example (titanic.c): worker task
staticints_service_success(char*uuid);intmain(intargc,char*argv[]){intverbose=(argc>1&&streq(argv[1],"-v"));zctx_t*ctx=zctx_new();void*request_pipe=zthread_fork(ctx,titanic_request,NULL);zthread_new(titanic_reply,NULL);zthread_new(titanic_close,NULL);// Main dispatcher loopwhile(true){// We'll dispatch once per second, if there's no activityzmq_pollitem_titems[]={{request_pipe,0,ZMQ_POLLIN,0}};intrc=zmq_poll(items,1,1000*ZMQ_POLL_MSEC);if(rc==-1)break;// Interruptedif(items[0].revents&ZMQ_POLLIN){// Ensure message directory existszfile_mkdir(TITANIC_DIR);// Append UUID to queue, prefixed with '-' for pendingzmsg_t*msg=zmsg_recv(request_pipe);if(!msg)break;// InterruptedFILE*file=fopen(TITANIC_DIR"/queue","a");char*uuid=zmsg_popstr(msg);fprintf(file,"-%s\n",uuid);fclose(file);free(uuid);zmsg_destroy(&msg);}// Brute force dispatchercharentry[]="?.......:.......:.......:.......:";FILE*file=fopen(TITANIC_DIR"/queue","r+");while(file&&fread(entry,33,1,file)==1){// UUID is prefixed with '-' if still waitingif(entry[0]=='-'){if(verbose)printf("I: processing request %s\n",entry+1);if(s_service_success(entry+1)){// Mark queue entry as processedfseek(file,-33,SEEK_CUR);fwrite("+",1,1,file);fseek(file,32,SEEK_CUR);}}// Skip end of line, LF, or CRLFif(fgetc(file)=='\r')fgetc(file);if(zctx_interrupted)break;}if(file)fclose(file);}return0;}
In the final part of the broker code (Example 4-60), we first check if the requested MDP service is defined or not, using an MMI lookup to the Majordomo broker. If the service exists, we send a request and wait for a reply using the conventional MDP client API. This is not meant to be fast, just very simple.
Example 4-60. Titanic broker example (titanic.c): try to call a service
staticints_service_success(char*uuid){// Load request message, service will be first framechar*filename=s_request_filename(uuid);FILE*file=fopen(filename,"r");free(filename);// If client already closed request, treat as successfulif(!file)return1;zmsg_t*request=zmsg_load(NULL,file);fclose(file);zframe_t*service=zmsg_pop(request);char*service_name=zframe_strdup(service);// Create MDP client session with short timeoutmdcli_t*client=mdcli_new("tcp://localhost:5555",FALSE);mdcli_set_timeout(client,1000);// 1 secmdcli_set_retries(client,1);// only 1 retry// Use MMI protocol to check if service is availablezmsg_t*mmi_request=zmsg_new();zmsg_add(mmi_request,service);zmsg_t*mmi_reply=mdcli_send(client,"mmi.service",&mmi_request);intservice_ok=(mmi_reply&&zframe_streq(zmsg_first(mmi_reply),"200"));zmsg_destroy(&mmi_reply);intresult=0;if(service_ok){zmsg_t*reply=mdcli_send(client,service_name,&request);if(reply){filename=s_reply_filename(uuid);FILE*file=fopen(filename,"w");assert(file);zmsg_save(reply,file);fclose(file);free(filename);result=1;}zmsg_destroy(&reply);}elsezmsg_destroy(&request);mdcli_destroy(&client);free(service_name);returnresult;}
To test this, start mdbroker and
titanic, and then run ticlient. Now start mdworker arbitrarily, and you should see the
client getting a response and exiting happily.
Some notes about this code:
Note that some loops start by sending, and others by receiving messages. This is because Titanic acts both as a client and a worker in different roles.
The Titanic broker uses the MMI service discovery protocol to send requests only to services that appear to be running. Since the MMI implementation in our little Majordomo broker is quite poor, this wonât work all the time.
We use an
inprocconnection to send new request data from thetitanic.requestservice through to the main dispatcher. This saves the dispatcher from having to scan the disk directory, load all request files, and sort them by date/time.
The important thing about this example is not its performance (which, although I havenât tested it, is surely terrible), but how well it implements the reliability contract. To try it, start the mdbroker and titanic programs. Then start the ticlient, and then start the mdworker echo service. You can run all four of these using the -v option to do verbose activity tracing. You can stop and restart any piece except the client, and nothing will get lost.
If you want to use Titanic in real cases, youâll rapidly be asking, âHow do we make this faster?â Hereâs what Iâd do, starting with the example implementation:
Use a single disk file for all data, rather than multiple files. Operating systems are usually better at handling a few large files than many smaller ones.
Organize that disk file as a circular buffer so that new requests can be written contiguously (with very occasional wraparound). One thread, writing full speed to a disk file, can work rapidly.
Keep the index in memory and rebuild the index at startup time, from the disk buffer. This saves the extra disk head flutter needed to keep the index fully safe on disk. You would want an
fsyncafter every message, or every N milliseconds if you were prepared to lose the last M messages in case of a system failure.Use a solid-state drive rather than spinning iron oxide platters.
Preallocate the entire file, or allocate it in large chunks, which allows the circular buffer to grow and shrink as needed. This avoids fragmentation and ensures that most reads and writes are contiguous.
And so on. What Iâd not recommend is storing messages in a database, not even a âfastâ key/value store, unless you really like a specific database and donât have performance worries. You will pay a steep price for the abstractionâ10 to 1,000 times over a raw disk file.
If you want to make Titanic even more reliable, duplicate the requests to a second server, and place it in a second location just far away enough to survive a nuclear attack on your primary location, yet not so far that you get too much latency.
If you want to make Titanic much faster but less reliable, store requests and replies purely in memory. This will give you the functionality of a disconnected network, but requests wonât survive a crash of the Titanic server itself.
Get ZeroMQ now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

