422
|
第
14
章
对边界框应该进行归一化,以便水平坐标和垂直坐标以及高度和宽度都在 0
到 1 的范围内。而且通常要预测高度和宽度的平方根,而不是直接的高度和
宽度值:通过这种方式,对于大边框的 10 像素错误将不会像对小边框的 10
像素错误一样受到惩罚。
MSE 通常作为成本函数可以很好地训练模型,但是评估模型对边界框的预测能力不是一
个很好的指标。最常用的度量指标是“交并比”(Intersection over Union, IoU):预测边
界框和目标边界框之间的重叠面积除以它们的联合面积(见图 14-23)。 在 tf.keras 中,
它是由 tf.keras.metrics.MeanIoU 类实现的。
交集
标签
预测
并集
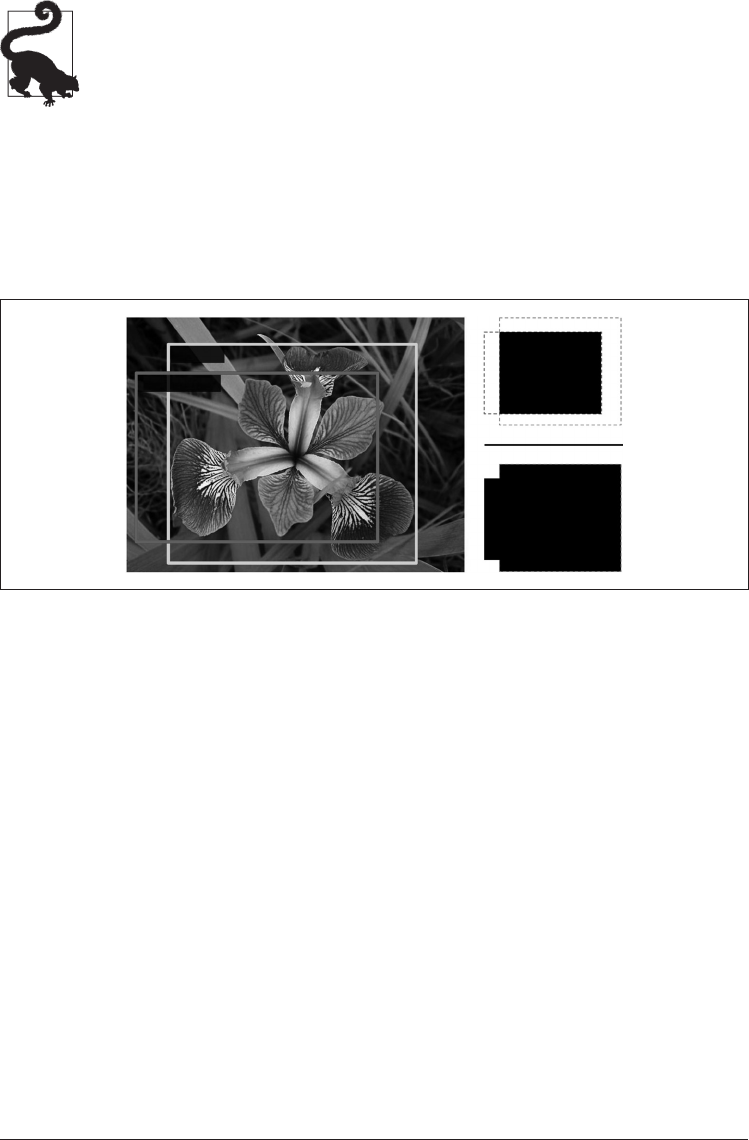
图 14-23:边界框的交并比(IoU)度量
对单个物体进行分类和定位是很好的,但是如果图像中包含多个物体(在花朵数据集中
通常如此)怎么办?
14.9 物体检测
在图像中对多个物体进行分类和定位的任务称为物体检测。直到几年前,一种通用的方
法是采用经过训练的 CNN 来对单个物体进行分类和定位,然后将其在图像上滑动,如
图 14-24 所示。在此示例中,图像被切成 6
×
8 的网格,我们显示了 CNN(黑色粗矩形)
在所有 3
×
3 区域中的滑动。当 CNN 看着图像的左上方时,它检测到最左边的玫瑰的一
部分,然后当它第一次向右移动了一步时,又检测到该玫瑰。在下一步中,它开始检测
最上面的玫瑰的一部分,然后再向右移动一步,便再次检测到它。然后,你将继续在整
个图像中滑动 CNN,查看所有 ...