32
|
第
1
章
1.5 机器学习的主要挑战
简单来说,由于你的主要任务是选择一种学习算法,并对某些数据进行训练,所以最可
能出现的两个问题不外乎是“坏算法”和“坏数据”,让我们先从坏数据开始。
1.5.1 训练数据的数量不足
要教一个牙牙学语的小朋友什么是苹果,你只需要指着苹果说“苹果”(可能需要重复这
个过程几次)就行了,然后孩子就能够识别各种颜色和形状的苹果了,简直是天才!
机器学习还没达到这一步,大部分机器学习算法需要大量的数据才能正常工作。即使是
最简单的问题,很可能也需要成千上万个示例,而对于诸如图像或语音识别等复杂问
题,则可能需要数百万个示例(除非你可以重用现有模型的某些部分)。
12
数据的不合理有效性
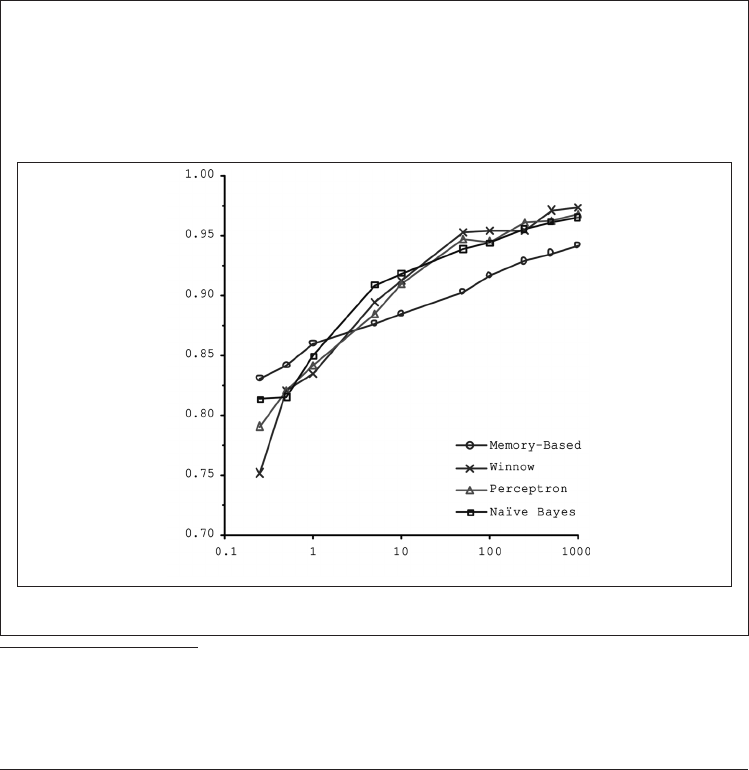
在 2001 年发表的一篇著名论文中,微软研究员 Michele Banko 和 Eric Brill 表明,给
定足够的数据,截然不同的机器学习算法(包括相当简单的算法)在自然语言歧义
消除这个复杂问题上
注 8
,表现几乎完全一致(如图 1-20 所 示 )。
文本精确度
百万个单词
图 1-20:数据与算法的重要性
注 9
注 8 :例如,根据上下文知道是写“to”“ two”还是“too”。
注 9 :图经 Michele Banko 和 Eric Brill 许可转载,“ Scaling to Very Very Large Corpora for Natural Language
Disambiguation ”,
Proceedings of the 39th Annual Meeting ...