536
|
第
18
章
是,它是功能更强大的算法的基础,例如
Actor-Critic
算法。(我们将在本章末尾简要讨
论 它 )。
现在,我们看看另一个流行的算法系列。PG 算法直接尝试优化策略来增加奖励,而我
们现在要看的算法则不太直接:智能体学习估计每个状态或每个状态中每个动作的预期
回报,然后把这些知识用于决定如何行动。为了理解这些算法,我们必须首先介绍马尔
可夫决策过程。
18.7 马尔可夫决策过程
在 20 世纪初期,数学家安德烈
·
马尔可夫(Andrey Markov)研究了无记忆的随机过程,
称为马尔可夫链。这个过程具有固定数量的状态,并且在每个步骤中它都从一种状态随
机演变到另一种状态。它从状态
s
演变为状态
s'
的概率是固定的,并且仅取决于 (
s
,
s'
),
而不取决于过去的状态(这就是为什么我们说系统没有记忆)。
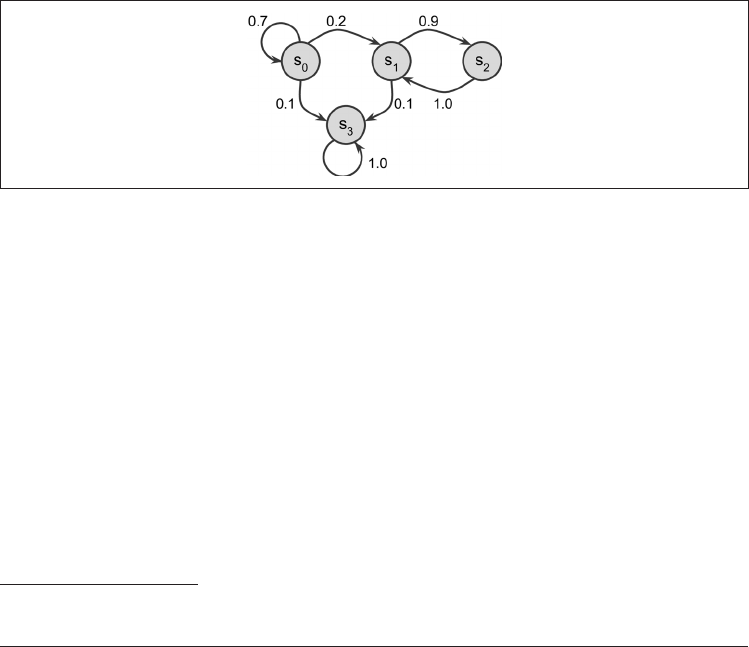
图 18-7 显示了具有四个状态的马尔可夫链的示例。
图 18-7:马尔可夫链的示例
假设该过程在状态
s
0
开始,并且有 70% 的机会在下一步继续保持该状态。最终它必然
会离开该状态,而且再也不会回来,因为没有其他状态指向
s
0
。如果它进入状态
s
1
,则很
可能会进入状态
s
2
(概率为 90%),然后立即返回状态
s
1
(概率为 100%)。它可以在这两
个状态之间交替多次,但是最终它会落入状态
s
3
并永久停留在那里(这是终端状态)。马
尔可夫链可以具有截然不同的动态过程,并且在热力学、化学、统计等领域大量使用。
马尔可夫决策过程最早是在 1950 年代由理查德
·
贝尔曼(Richard Bellman)描述的 ...