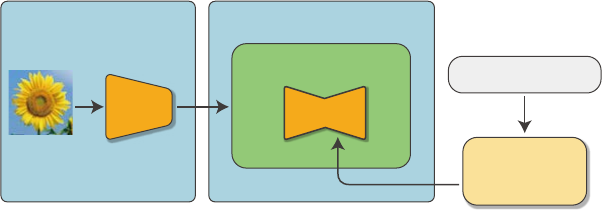
수)가 같았습니다. 각 시각의 데이터는 모두 이미지와 동일한 벡터 공간, 즉 픽셀 공간에서 처
리된다는 뜻입니다. 반면 스테이블 디퓨전은 잠재 변수의 공간, 즉 잠재 공간
latent
space
에서 확
산 모델을 처리합니다.
스테이블 디퓨전은 인코더를 사용하여 픽셀 공간에서 잠재 공간으로 변환합니다. 인코더에는
VAE
에서 사용한 모델을 사용할 수 있고 잠재 변수의 차원 수를 줄임으로써 확산 모델에서 처 ...
Become an O’Reilly member and get unlimited access to this title plus top books and audiobooks from O’Reilly and nearly 200 top publishers, thousands of courses curated by job role, 150+ live events each month, and much more.