This is probably the most widely used classification algorithm, and the first algorithm that a machine learning practitioner usually tries when given a classification problem. It performs well when data is linearly separable or approximately linearly separable. Even if it is not linearly separable, it might be possible to convert the linearly non-separable features into separable ones and apply logistic regression afterward.
In the following instance, data in the original space is not linearly separable, but they become separable in a transformed space created from the interaction of two features:
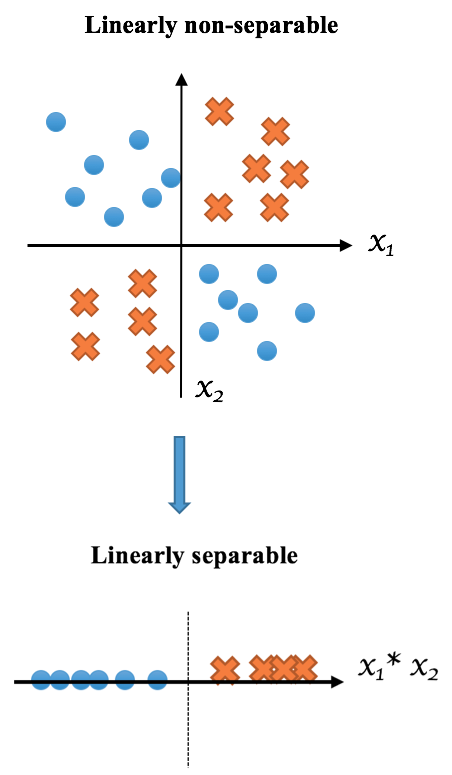
Also, logistic regression ...

