May 2017
Beginner to intermediate
596 pages
15h 2m
English
One of the important paradelvems on which the Hadoop framework processes large datasets is using the MapReduce programming model. Again, MapReduce also uses the master-slave concept, in which the input file is first broken into smaller ones and then each piece is fed to worker nodes, which process (map task) the data and then the master collects it (reduce task) and sends it back. This is depicted in a pictorial fashion in the following figure:
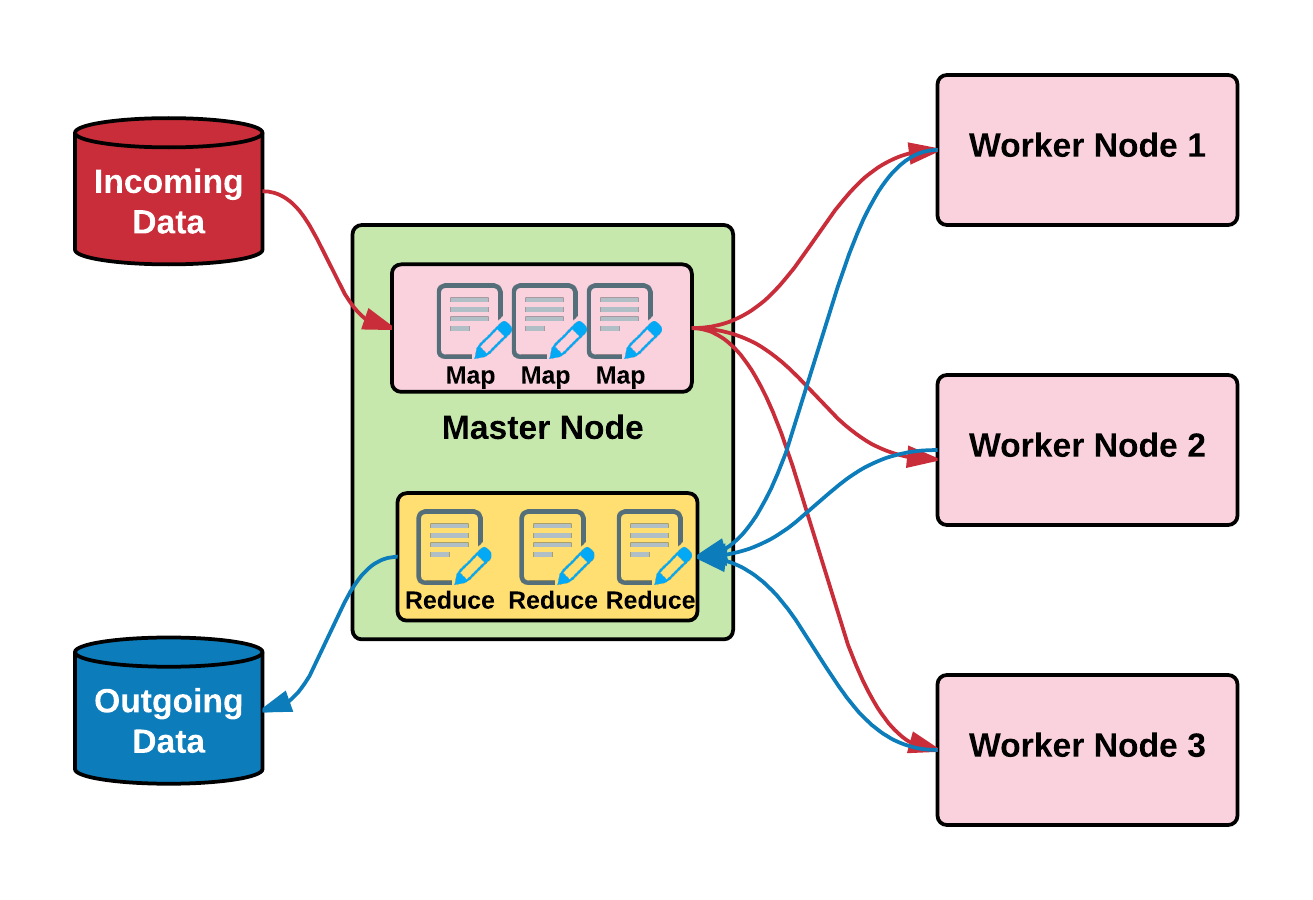
As shown in the preceding figure, Map sends the queries (code to data) to the nodes and then reduce collects the results and collates ...