February 2018
Intermediate to advanced
262 pages
6h 59m
English
Keep a fraction of the dataset for the test split, then divide the entire dataset into k-folds where k can be any number, generally varying from two to ten. At any given iteration, we hold one block for validation and train the algorithm on the rest of the blocks. The final score is generally the average of all the scores obtained across the k-folds. The following diagram shows an implementation of k-fold validation where k is four; that is, the data is split into four parts:
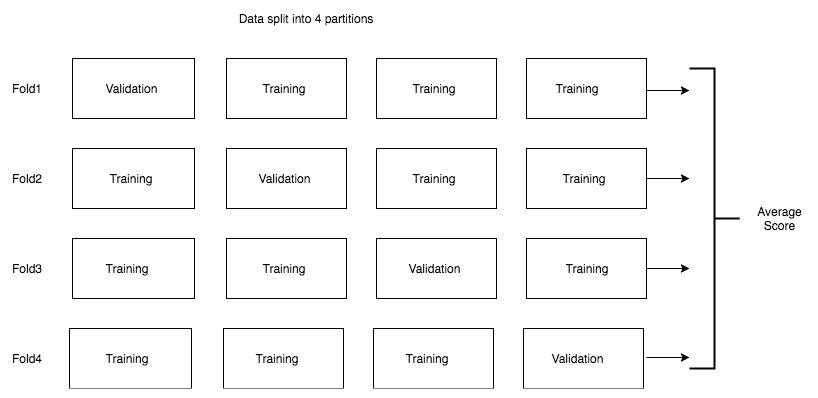
One key thing to note when using the k-fold validation dataset is that it is very expensive, because you run the algorithm several times on different ...
Read now
Unlock full access






