184
|
第
8
章
模型整体上得到了改进,预测指标达到了
0.98
。此时情况变得更加困难,因为最容易的方
法已经用过了,但是仍有改进的空间。看看特征重要度有何变化:
rf_model = triangle_model.stages[-1]
plot_feature_importance(fields, rf_model.featureImportances)
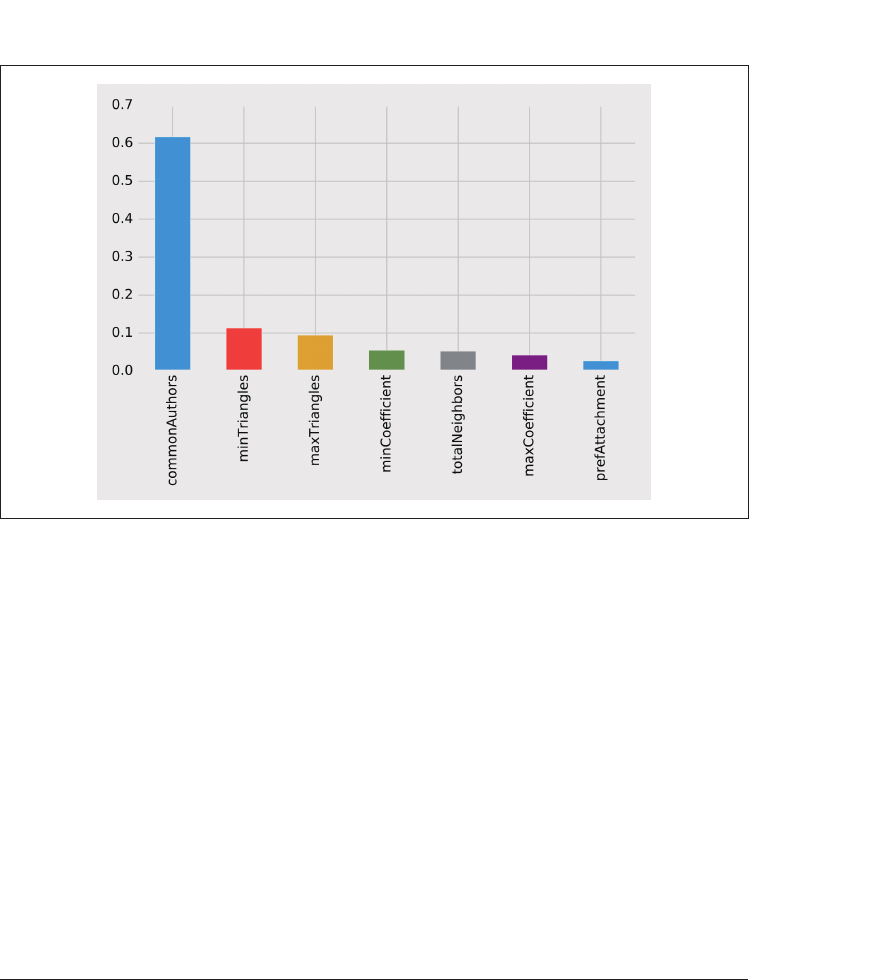
运行该函数,结果如图
8-14
所示。共同作者特征对模型的影响仍然最大。也许需要探索新
领域了,看看添加社团信息后会发生什么。
图 8-14:三角形模型的特征重要度
8.3.9
预测链接
:
社团发现
假设即使同一社团中的节点之间没有链接,它们之间存在链接的可能性也更大。此外,我
们认为社团越紧密,存在链接的可能性越大。
首先,使用
Neo4j
中的标签传播算法计算更粗粒度的社团。执行以下查询可实现这一操
作。对于训练集,该查询将把社团存储在
partitionTrain
性质中;对于测试集,则存储在
partitionTest
性质中:
CALL algo.labelPropagation("Author", "CO_AUTHOR_EARLY", "BOTH",
{partitionProperty: "partitionTrain"});
CALL algo.labelPropagation("Author", "CO_AUTHOR", "BOTH",
{partitionProperty: "partitionTest"});