May 2019
Intermediate to advanced
442 pages
11h 36m
English
We went through a couple of strategies for vertically sharding Prometheus, but there's a problem we still haven't addressed: scaling requirements tied to a single job. Imagine that you have a job with tens of thousands of scrape targets inside one datacenter, and there isn't a logical way to split it any further. In this type of scenario, your best bet is to shard horizontally, spreading the same job across multiple Prometheus servers. The following diagram provides an example of this type of sharding:
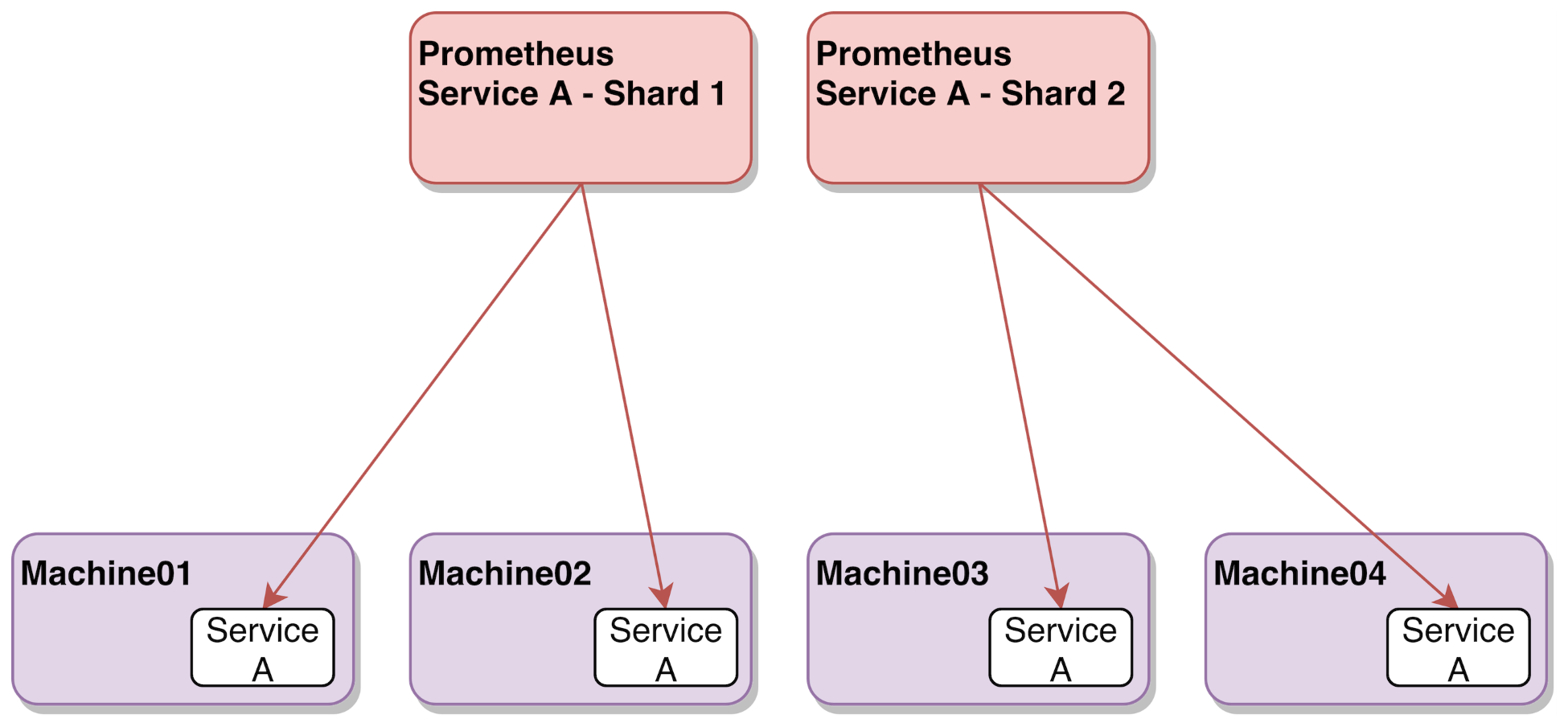
To accomplish this, we must rely on the hashmod relabeling ...
Read now
Unlock full access






