September 2002
Intermediate to advanced
656 pages
22h 14m
English
In this overview chapter, we’ve focused on how two web applications (web browsers and web servers) send messages back and forth to implement basic transactions. There are many other web applications that you interact with on the Internet. In this section, we’ll outline several other important applications, including:
HTTP intermediaries that sit between clients and servers
HTTP storehouses that keep copies of popular web pages close to clients
Special web servers that connect to other applications
Special proxies that blindly forward HTTP communications
Semi-intelligent web clients that make automated HTTP requests
Let’s start by looking at HTTP proxy servers , important building blocks for web security, application integration, and performance optimization.
As shown in Figure 1-11, a proxy sits between a client and a server, receiving all of the client’s HTTP requests and relaying the requests to the server (perhaps after modifying the requests). These applications act as a proxy for the user, accessing the server on the user’s behalf.
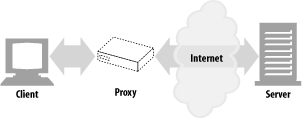
Figure 1-11. Proxies relay traffic between client and server
Proxies are often used for security, acting as trusted intermediaries through which all web traffic flows. Proxies can also filter requests and responses; for example, to detect application viruses in corporate downloads ...