May 2018
Intermediate to advanced
576 pages
14h 42m
English
When we discussed the cluster assumption, we also defined the low-density regions as boundaries and the corresponding problem as low-density separation. A common supervised classifier which is based on this concept is a Support Vector Machine (SVM), the objective of which is to maximize the distance between the dense regions where the samples must be. For a complete description of linear and kernel-based SVMs, please refer to Bonaccorso G., Machine Learning Algorithms, Packt Publishing; however, it's useful to remind yourself of the basic model for a linear SVM with slack variables ξi:
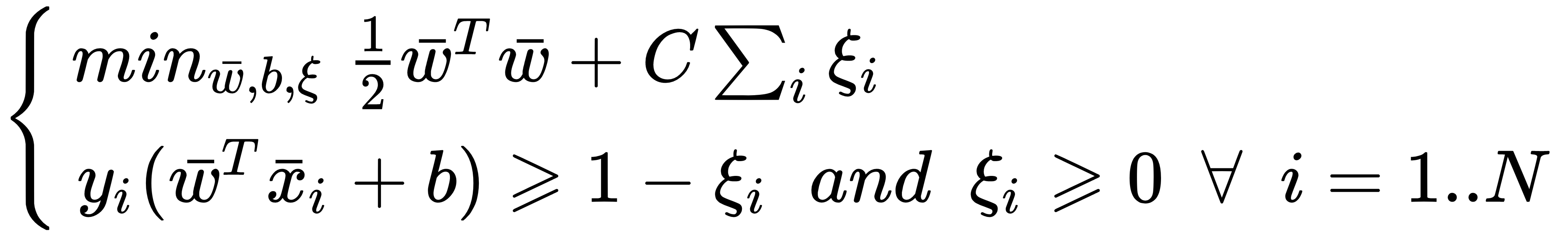
This model ...
Read now
Unlock full access






