May 2018
Intermediate to advanced
576 pages
14h 42m
English
A more robust way to improve the performance of SGD when plateaus are encountered is based on the idea of momentum (analogously to physical momentum). More formally, a momentum is obtained employing the weighted moving average of subsequent gradient estimations instead of the punctual value:
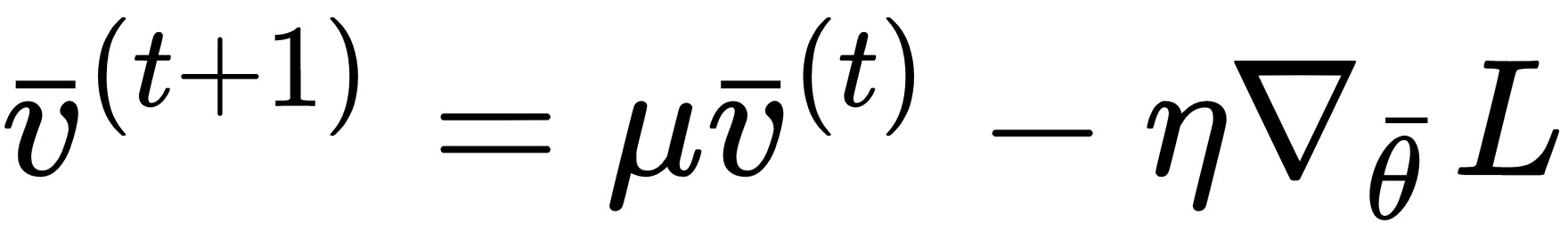
The new vector v(t), contains a component which is based on the past history (and weighted using the parameter μ which is a forgetting factor) and a term referred to the current gradient estimation (multiplied by the learning rate). With this approach, abrupt changes become more difficult, and when the exploration leaves ...
Read now
Unlock full access






