January 2019
Intermediate to advanced
386 pages
11h 13m
English
In the Dynamic programming section, we'll describe how to estimate the value function,  , given a policy, π (planning). MC does this by playing full episodes, and then averaging the cumulative returns for each state over the different episodes.
, given a policy, π (planning). MC does this by playing full episodes, and then averaging the cumulative returns for each state over the different episodes.
Let's see how it works in the following steps:
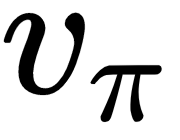 table with some value for all states
table with some value for all states