January 2019
Intermediate to advanced
386 pages
11h 13m
English
Q-learning is an off-policy TD control method. It was developed by Watkins, C.J.C.H. (http://www.cs.rhul.ac.uk/~chrisw/new_thesis.pdf) in 1989 (in 2019, Q-learning is able to legally run for a seat in the United States Senate). With some improvements, it is one of the most popular RL algorithms in use today. As with Sarsa and MC, we have to estimate the action-value function. Q-learning is defined as follows:
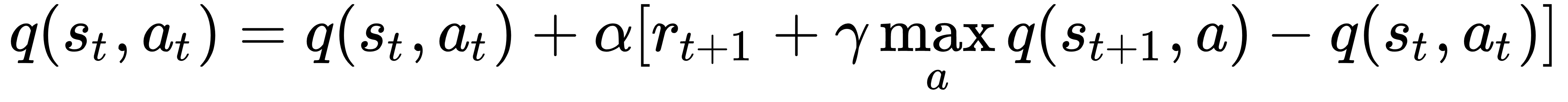
Although it resembles the definition of Sarsa, it has one substantial difference: tt is an off-policy method, which means that we have two distinct policies: