January 2019
Intermediate to advanced
386 pages
11h 13m
English
Imagine that the majority of the actions, a, starting from state, s, have true action-values,  . That is, the real return for each action starting from the s state is 0. Unfortunately, we don't know the true action-values and instead we try to estimate them, hoping that our estimation will eventually converge toward the optimum. Our estimations,
. That is, the real return for each action starting from the s state is 0. Unfortunately, we don't know the true action-values and instead we try to estimate them, hoping that our estimation will eventually converge toward the optimum. Our estimations, 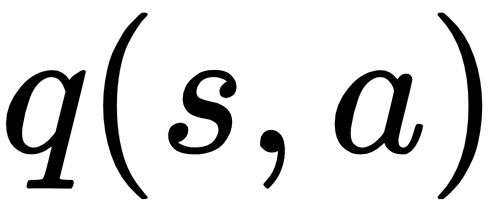 , are uncertain – some estimations might be slightly above 0, while others might be slightly below. And here comes the issue. When we compute the estimation of each state/action pair ...
, are uncertain – some estimations might be slightly above 0, while others might be slightly below. And here comes the issue. When we compute the estimation of each state/action pair ...