2
2.1.2
パラメータ更新の仕組み
個々の学習手法で用いるデータセットや学習の目的は異なりますが、LLM のパラメータを
調整するという点では共通しています。事前学習から始まり徐々にパラメータを調整していく
ことで、LLM は高い性能を発揮できるようになります。パラメータの調整では、訓練用の
データセット全体に対する損失関数を最小化することを目指します。
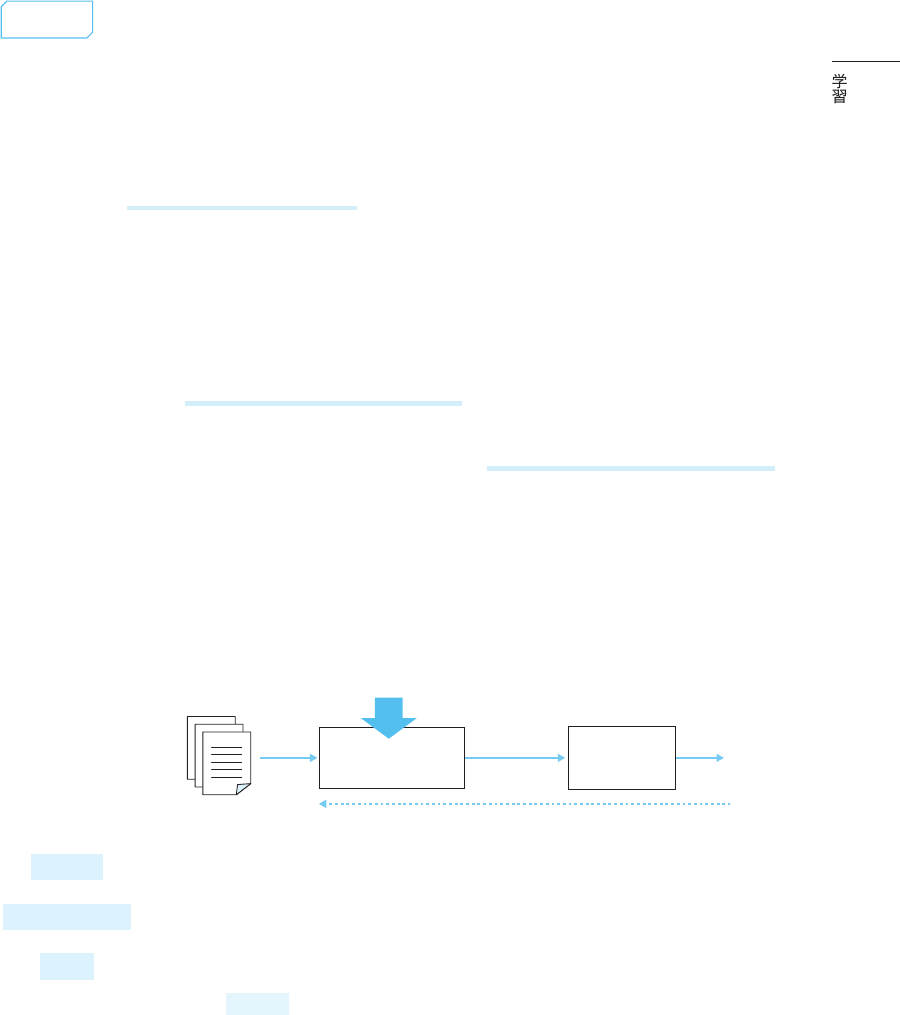
図2.1.2 に、損失関数(Loss Function)の最小化による学習の様子を示します。損失関数
はモデルの予測と実際の値の差を数値化したもので、この差が小さいほどモデルの予測が正確
であることを示します。個々の学習手法では、異なるデータセットや損失関数を使用します。
例えば、指示チューニングでは、タスク指示と回答のペアから構成されるデータセットを使用
し、損失関数には交差エントロピー損失関数を使用します。しかし、損失関数が異なってもパ
ラメータを更新する仕組み自体は学習手法間で共通です。
パラメータ更新は、勾配降下法(Gradient Descent)をベースとするアルゴリズムによって
実現されます。勾配降下法では損失関数の勾配を計算し、その勾配に従って個々のパラメータ
を更新します。さらに、勾配を効率よく計算するために、誤差逆伝播法(Backpropagation)
と呼ばれるアルゴリズムが用いられます。誤差逆伝播法は、損失(誤差)を逆伝播させること
で、各層の勾配を計算します。
次節以降では、個々の学習手法について詳しく説明し、その後、パラメータ更新の共通の仕 ...






