2
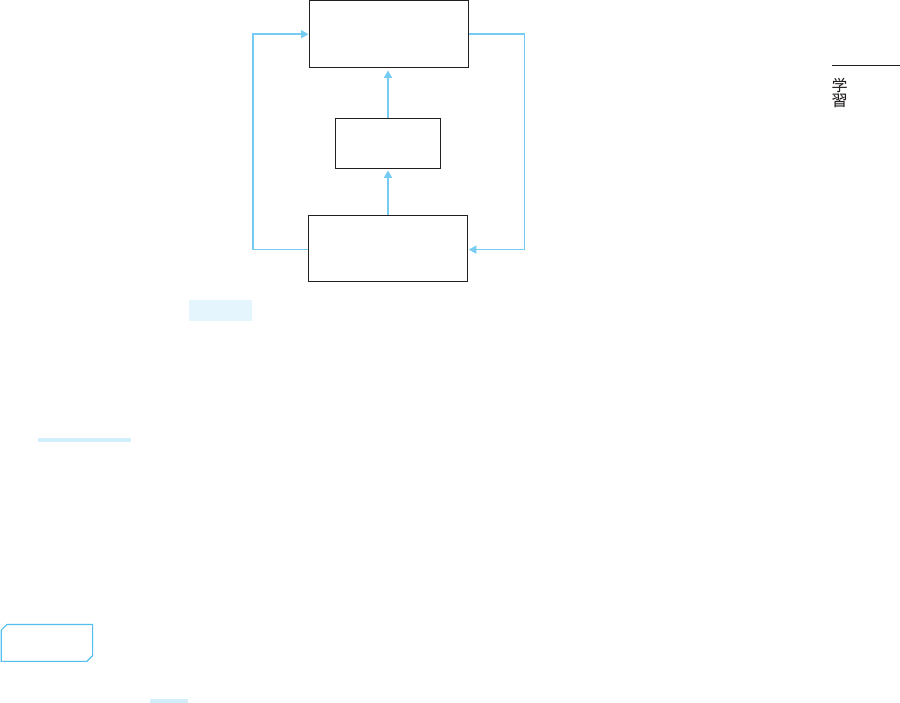
図2.4.1
図2.4.1 に、RLHF におけるエージェントと環境の相互作用を示します。選択された行動に
対して環境は報酬を与え、エージェントはその報酬を最大化するように学習します。RLHFで
は、報酬モデルを用いて人間のフィードバックを数値化したスコアを報酬として使用します。
このため、強化学習を行う事前準備として、報酬モデルの構築とその事前学習が必要となりま
す。
以降、本節では報酬モデルについて説明した後、RLHFの学習プロセスについて詳しく説明
します。
2.4.3
報酬モデル
強化学習では、報酬を最大化することが目的となります。LLMの場合、人間の好みにより
適合した出力が得られるほど報酬が高くなります。しかし、人間の好みに適合しているか否か
を毎回人手でチェックすることは現実的ではありません。そこで、自動的に報酬を計算するた
めの報酬モデルを事前に準備し、使用します。
報酬モデルは、プロンプトとLLM の生成したテキストを入力とし、そのテキストの質や適
切さを評価するスコアを出力します。出力するスコアは高いほど人間の好みに適合しているこ
とを示し、低いほど適合していないことを示します。RLHFでは、強化学習の前に報酬モデル
を事前学習させ、そのスコアを用いてLLM の学習を行います。
報酬モデルは、通常、事前学習済みの言語モデルをベースとし、最後に回帰層を追加して訓 ...






