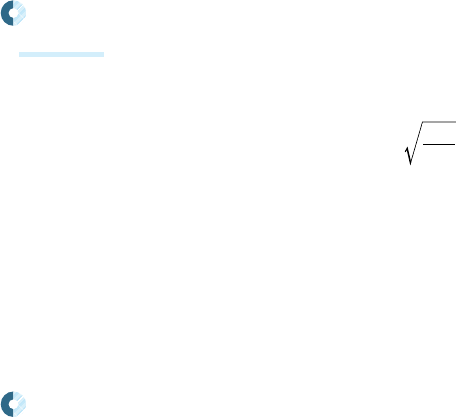He初期化 [He et al. 2015b] は、活性化関数がReLUやその派生系(LeakyReLU、PReLU
など)の場合に適しています。この方法では、重みを次のように初期化します。
,N
n
0
2
W
in
+
dn
ここで、
W
は重み行列、
N
は正規分布、
n
in
は入力ユニット数を表します。He初期化は
ReLU関数の特性を考慮して設計されており、深いニューラルネットワークの学習を安定化さ
せます。
現在、Transformerを含む多くの深層学習モデルでは活性化関数にReLUまたはその派生系
が使用されています。このため、He初期化が一般的に用いられています。
ゼロ初期化
バイアス項については、通常ゼロで初期化します。これは対称性を保ち、学習の初期段階で
各ニューロンが同じように振る舞うようにするためです。ただし、出力層のバイアス項は、問
題に応じて適切な値に初期化することがあります。
106
Become an O’Reilly member and get unlimited access to this title plus top books and audiobooks from O’Reilly and nearly 200 top publishers, thousands of courses curated by job role, 150+ live events each month, and much more.
O’Reilly covers everything we've got, with content to help us build a world-class technology community, upgrade the capabilities and competencies of our teams, and improve overall team performance as well as their engagement.
Julian F.
Head of Cybersecurity
I wanted to learn C and C++, but it didn't click for me until I picked up an O'Reilly book. When I went on the O’Reilly platform, I was astonished to find all the books there, plus live events and sandboxes so you could play around with the technology.
Addison B.
Field Engineer
I’ve been on the O’Reilly platform for more than eight years. I use a couple of learning platforms, but I'm on O'Reilly more than anybody else. When you're there, you start learning. I'm never disappointed.
Amir M.
Data Platform Tech Lead
I'm always learning. So when I got on to O'Reilly, I was like a kid in a candy store. There are playlists. There are answers. There's on-demand training. It's worth its weight in gold, in terms of what it allows me to do.