SEO—short for Search Engine Optimization—is the set of techniques used to drive web traffic to websites. These techniques include optimization of the code, content, and organization of a site. While some SEO strategies do involve paying for inbound links, generally SEO is considered to exclude advertising.
Note
Advertising on search engines is thought of as Search Engine Marketing (SEM). SEO campaigns should often be used in tandem with SEM as I explain in Chapter 2. Advertising programs, such as Google AdWords (see Part III), can very effectively generate traffic via ads placed on web pages as well as on search engine result pages.
Most web businesses need traffic to succeed. Some websites depend on broad, general traffic. These businesses need hundreds of thousands or millions of visitors per day to prosper and thrive.
Other web businesses are looking for high-quality, targeted traffic. This traffic is essentially like a prequalified sales prospect—they are already looking for and interested in your offering.
This chapter tells you what you need to know, and explains the tools you’ll use, to draw more traffic to your site. Google is by far the most important search engine, so most SEO targets Google (but what works for Google also works for the other search engines). You’ll learn how to effectively use PageRank and Google itself. Effective use of SEO means understanding how Google works, how to boost placement in Google search results, and how not to offend Google. You’ll also learn how to best organize your web pages and websites, apply SEO analysis tools, establish effective SEO best practices, and more.
When you approach SEO, make sure you’ve worked through the analysis I suggested in Chapter 2 to understand the characteristics of the traffic that you need. Then use the techniques explained in this chapter to boost your traffic—and your business.
Originally fairly narrowly conceived as a set of techniques for rising to the top of search engine listings, Search Engine Optimization (SEO) has conceptually expanded to include all possible ways of promoting web traffic.
Learning how to construct websites, web content, and pages to improve—and not harm—the search engine placement of those websites and web pages has become a key component in the evolution of SEO. This central goal of SEO is sometimes called core SEO, as opposed to broader, noncore, web traffic campaigns, which may include lobbying and paying for links.
Effective SEO requires understanding that there needs to be a balance between attracting search engines and interesting human visitors. One without the other does not succeed. There must be balance between the yin of the search bot and the yang of the real human site visitor.
The basics of SEO involve these steps:
Understanding how your pages are viewed by search engine software
Creating content that is attractive to the search engine indexing
Taking common-sense steps to make sure that the way your pages are coded is optimized from the viewpoint of these search engines
Note
Fortunately, this often means practicing good design, which makes your sites easy to use for human visitors as well. In addition, software is becoming available that automates the nuts and bolts of SEO page coding. For example, you can optimize the HTML tagging of a WordPress blog for SEO using the All-in-One SEO plug-in.
Organizing your site in a way that makes sense to the search engine index
Avoiding some overaggressive SEO practices that can get your site blacklisted by the search engines
Search engine placement means where a web page appears in an ordered list of search query results. It’s obviously better for pages to appear higher up and toward the beginning of the list returned by the search engine in response to a user’s query.
Not all queries are created equal, so part of effective SEO is to understand which queries matter to a specific website. It’s relatively easy to be the first search result returned for a query that nobody else cares about. On the other hand, it’s very tough to become a top-ranking response to a topical and popular search query that reflects the interest of millions of people (and has a corresponding number of search results all competing for visibility).
Clearly, driving traffic to a website can make the difference between commercial success and failure. SEO experts have come to look at search engine placement as only one of their tools—and to look at the broader context of web technologies and business mechanisms that help create and drive traffic.
SEO has become an advertising discipline that must be measured using the metrics of cost effectiveness that are applied to all advertising techniques.
If you understand SEO, you have an edge. It pays to nurture this understanding—whether you are coding your web pages yourself, working with in-house developers, or outsourcing your web design and implementation.
There may be some sites that do just fine without consciously considering SEO. But by intentionally developing a plan that incorporates SEO into your websites and web pages, your web properties will outrank others that do not.
Just as success begets success in the brick-and-mortar world, online traffic begets traffic. What you plan to do with the traffic, and how you plan to monetize it, are other issues. Making money with web content is considered in Chapters 5 and 6.
One way to look at this is that sites that use core SEO have an incrementally higher ranking in search results. These sites don’t make gauche mistakes that cost them points in search engine ranking. They use tried-and-true SEO techniques to gain points for each web page.
Page by page, these increments give you an edge.
This edge is your SEO advantage.
SEO can drive more traffic to your website. If you plan carefully, you can also affect the kind and quality of traffic driven to your site. This means that you need to consider SEO as part of your general market research and business plan, as explained in Chapter 2. Sure, most businesses want traffic—but not just any traffic. Just as the goal of a brick-and-mortar business is to have qualified customers—ones with money in their pocket who are ready to buy when they walk in the door—an online business wants qualified traffic.
Qualified traffic is not just any traffic. It is made up of people who are genuinely interested in your offering, who are ready to buy it, and who have the means to buy it. This implies that to successfully create an SEO campaign, you need to plan. You need to understand your ideal prospect and know her habits, and create a step-by-step scheme to lure her to your site, where she can be converted to a customer. It should be natural and easy to perform this kind of planning if you’ve first followed the marketing plan suggestions in Chapter 2.
SEO cannot spin gold from straw or make a purse out of a sow’s ear. Garbage sites—those that have come to be known as spam websites—will not draw huge amounts of traffic. Or if they do, these sites won’t draw traffic for long. Google and other search engines will pull the plug as soon as they detect what is going on.
Note
There’s a web content arms race going on, with spammers and malware creators on one side and Google and other content indexers and evaluators on the other. For Google and other search engines to stay in business, the results they deliver have to be meaningful to users. This means that there’s only so much content garbage that Google will put up with.
Just as email spammers keep trying to outwit email filters, and filters keep getting better in response, content spammers and Google are involved in an arms race.
Your goal with SEO should not involve content spam, sometimes referred to as black hat SEO. Instead, be one of the good guys, a white hat SEO practitioner. SEO skills are SEO skills whether the hat is black or white. But use your white hat SEO skills to draw even more traffic to sites that are already good and useful. In other words, SEO should be used in an ethical and legitimate fashion to add genuinely interesting and valuable content—and not as part of a scam to rip people off!
SEO needs to be regarded as an adjunct to the first law of the web: good content draws traffic. There is no substitute for content that people really want to find.
While SEO best practices should always be observed, there needs to be a sense of proportion in how SEO is used. It may not make sense to create a “Potemkin village” using SEO to draw traffic to a site if the site itself doesn’t yield high returns. In other words, SEO that is costly to implement is becoming regarded as one more aspect of advertising campaign management—and subject to the same discipline of cost-benefit analysis applied to all other well-managed advertising campaigns.
You’ll find a wide range of SEO analysis tools available to help you optimize your web pages and sites:
- Free tools
Free tools generally tackle a single piece of the SEO puzzle, such as generating good keywords, understanding how Google operates on specific sites and keywords, checking who links to your sites, and displaying rankings in multiple search engines at once.
- Google Webmaster Tools
The Google Webmaster Tools, which are free and were partially explained in Chapter 3, provide many of the analysis features of third-party, one-off free tools.
- Commercial SEO analysis software
Commercial software costs money to license (obviously!) and is mainly intended for administration of multiple SEO-improved sites.
There are a myriad of free SEO tools available, and there are many sites that list these free tools. (The compendium sites are generally supported by advertising, and must therefore practice good SEO themselves to be successful!)
Some good sites that list (and provide links) to free SEO analysis tools are http://www.trugroovez.com/free-seo-tools.htm, http://www.webuildpages.com/tools/, and http://www.seocompany.ca/tool/11-link-popularity-tools.html.
Some of the most useful (and free!) single-purpose SEO tools are:
- NicheBot
A keyword discovery tool that helps pinpoint the right keywords for optimization
Note
As I mentioned in Chapter 2, keyword lists such as those generated by NicheBot are useful for marketing purposes.
- The SERPS Tool
The SERPS (or search engine positioning) tool helps you discover your ranking across Google and other major search engines in one fell swoop
- Meta Tag Analyzer
Checks meta information for errors and relevance to page content
These tools can definitely be time-savers, particularly if you have a large amount of content you need to optimize. The price is certainly right!
Individual tools also can serve as a reality check—by running your pages through one of these tools, you can get a pretty good feeling for how well you have optimized a page. However, you should bear in mind that there is nothing that one of these tools can do for you that also cannot be done by hand given the knowledge you learn from this chapter.
Individually, SEO analysis tools available on the web can help you with your SEO tasks. However, to get the most from these tools, you need to understand underlying SEO concepts as explained in this chapter before you use these tools.
Over time, as you progress with SEO, you will probably accumulate your own favorite SEO analysis toolkit.
The Google Webmaster Tools provide several features that help with your inspection and analysis of your websites and pages. For information about starting the tools and launching them in reference to a specific site, see Chapter 3.
Formerly, many of the tools needed for effective SEO work had to be found piecemeal. While some SEO practitioners still prefer their own toolkits assembled from the web resources mentioned in Free Tools, the truth is that most essential tasks can be performed using the Google Webmaster Tools.
The most important analysis tools are “Crawl errors” and “HTML suggestions” (both in the Diagnostics tab) and “Your site on the web.”
As shown in Figure 4-1, the crawl errors page shows you errors in your URLs as listed in your site map (see Taking Advantage of Site Mapping). In addition, the report will show you various other kinds of problems with the links (URLs) in your site—and most important, links that lead to HTTP 404 errors because the file can’t be found.
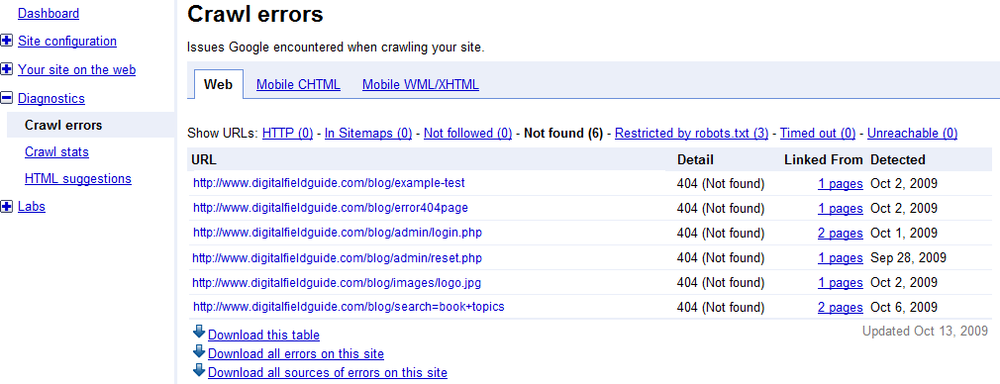
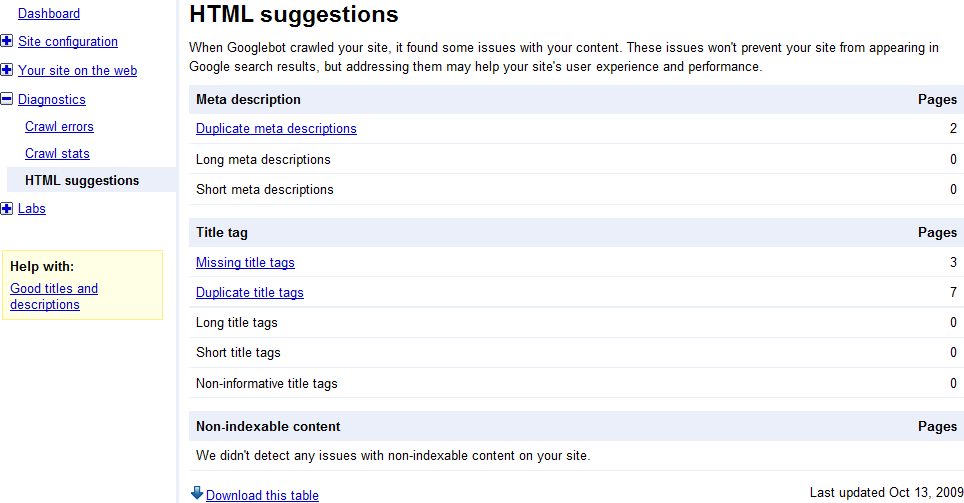
The HTML suggestions page shows you potential problems with meta descriptions, title tags, and whether there is any content that is not indexable. As with the crawl errors page, any reported errors should be taken as the starting place for investigation rather than gospel.
Figure 4-2 shows an HTML suggestions report listing some meta description and title tag problems.
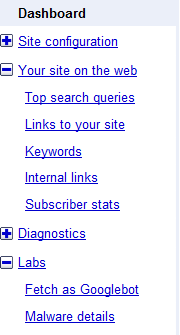
The “Your site on the web” page (Figure 4-3) helps give webmasters a window into how their sites appear to the Googlebot. This page shows top search queries, inbound links to your site, the anchor text of those links (i.e., the text that is visible in the hyperlink as opposed to the destination URL), and the most common words found on your site.
It’s important to be clear that the link text appears on the sites that link to you. Inbound linking plays a very important role in Google’s evaluation of your site, and the anchor text that accompanies links is what the bot uses to understand other sites’ ideas about your site. Anchor text that is not descriptive, for example, “Click here,” doesn’t help the bot. If you find sites that are linking to you with undescriptive anchor text, it’s good SEO practice to work with these sites to improve the quality of these links.
“Your site on the web” also provides information about important keywords found on your pages, as well as keywords used in external links to your site. This is a great place to see how well the content is optimized for your target keywords. If they’re not on the list, or not high on the list, it’s really easy to see where more work is needed.
Note
Even if you’re not interested in SEO (but who isn’t?!), it’s worth running “Your site on the web” from time to time and glancing at the Keywords tab. If strange terms like hydrocodone and prescription have crept into the keyword table, it is likely that you’ve been hacked (assuming you don’t sell drugs on your site). Spam text of this sort may not be visible to human viewers of your site, so it is good to have a mechanism for making sure you haven’t been hacked.
Commercially licensed SEO analysis software is unlikely to prove worth its cost unless you are in the business of performing SEO for numerous websites and a great deal of content, or for a major enterprise.
If the advertising for this kind of software claims too much, beware!
If you do want to look into licensed SEO software, some of the better-known commercial SEO analysis products are:
- Keyword Elite
- SEO Elite
- Lyris HQ
Provides a hosted suite of integrated web tools that includes marketing services, email, search marketing, web analytics, and web content management (CMS)
- SEO Administrator
Analysis tools are extremely important, not so much for the numbers they provide as for the insights that webmasters can get into improving the usability of their sites. You’ll find material in Chapter 13 about Google Analytics.
Get Google Advertising Tools, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

