288 | Capítulo 11: Treinando Redes Neurais Profundas
o risco de se sobreajustar ao conjunto de treinamento). Finalmente, eles também avaliaram
a parametric leaky ReLU (PReLU), em que α está autorizado a ser aprendido durante o
treinamento (em vez de ser um hiperparâmetro, ele se torna um parâmetro que pode ser
modificado por retropropagação como qualquer outro parâmetro). Isso supera o ReLU
em conjuntos de dados com grandes imagens, mas em conjuntos de dados menores ele
corre o risco de se sobreajustar ao conjunto de treinamento.
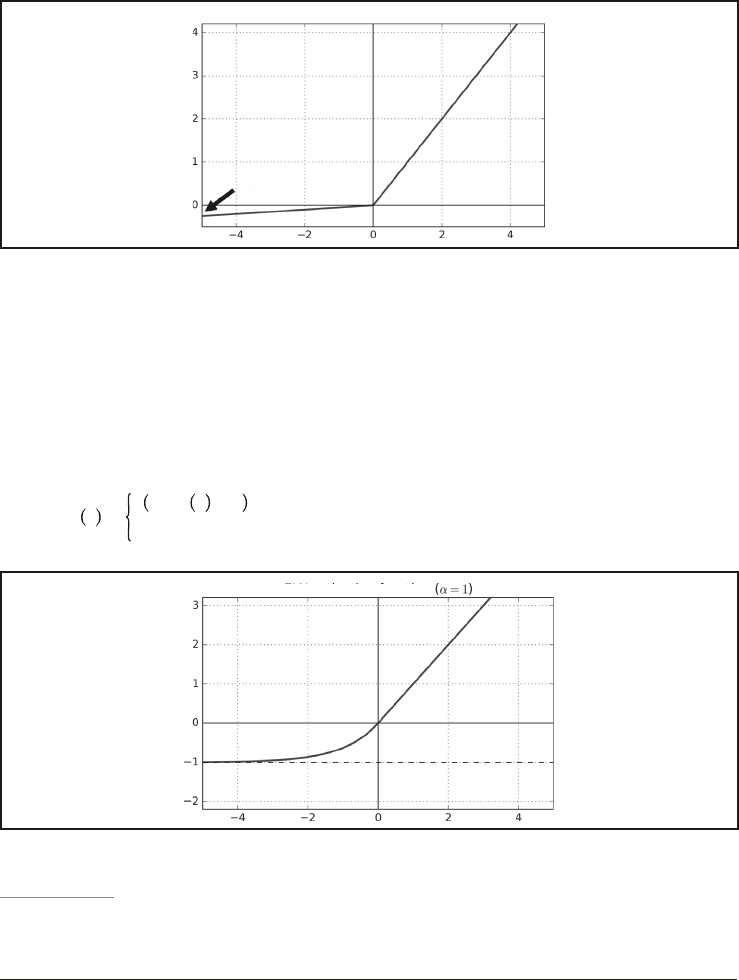
Função de ativação Leaky ReLU
Vazamento
Figura 11-2. Leaky ReLU
Por último, mas não menos importante, um artigo de 201 ...






