December 2018
Beginner to intermediate
684 pages
21h 9m
English
To propagate the update back to the output layer weights, we use the gradient of the loss function the J, with respect to the weight matrix, as follows:
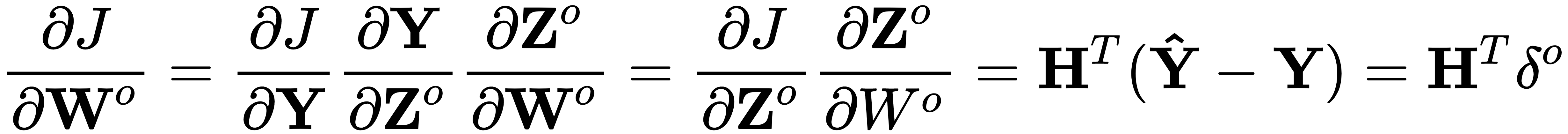
We can now define output_weight_gradient and output_bias_gradient accordingly, both taking the loss gradient, δo, as input:
def output_weight_gradient(H, loss_grad): """Gradients for the output layer weights""" return H.T @ loss_graddef output_bias_gradient(loss_grad): """Gradients for the output layer bias""" return np.sum(loss_grad, axis=0, keepdims=True)