December 2018
Beginner to intermediate
684 pages
21h 9m
English
The neural network comprises a set of nested functions as highlighted precedingly. Hence, the gradient of the loss function with respect to internal, hidden parameters is computed using the chain rule of calculus.
For scalar values, given the functions z = h(x) and y = o(h(x)) = o (z), we compute the derivative of y with respect to x using the chain rule, as follows:
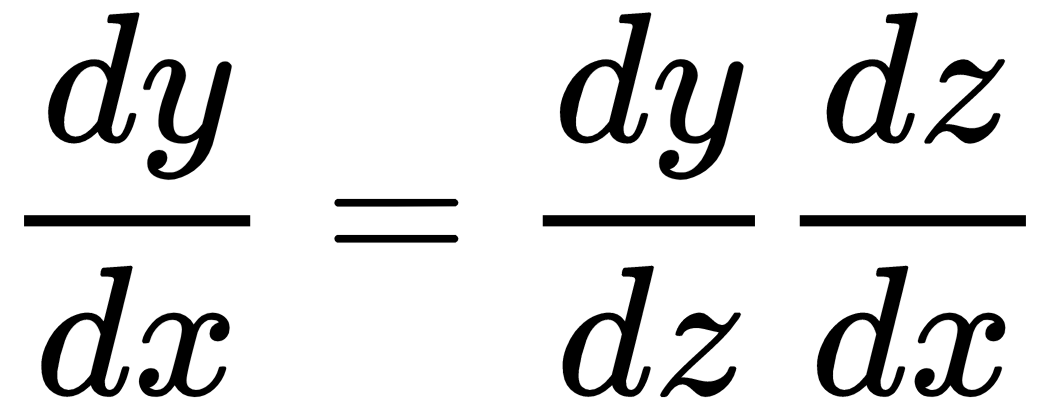
For vectors, with z ∈ Rm and x ∈ Rn so that the hidden layer, h, maps from Rn to Rm and z = h(x) and y = o (z), we get the following:
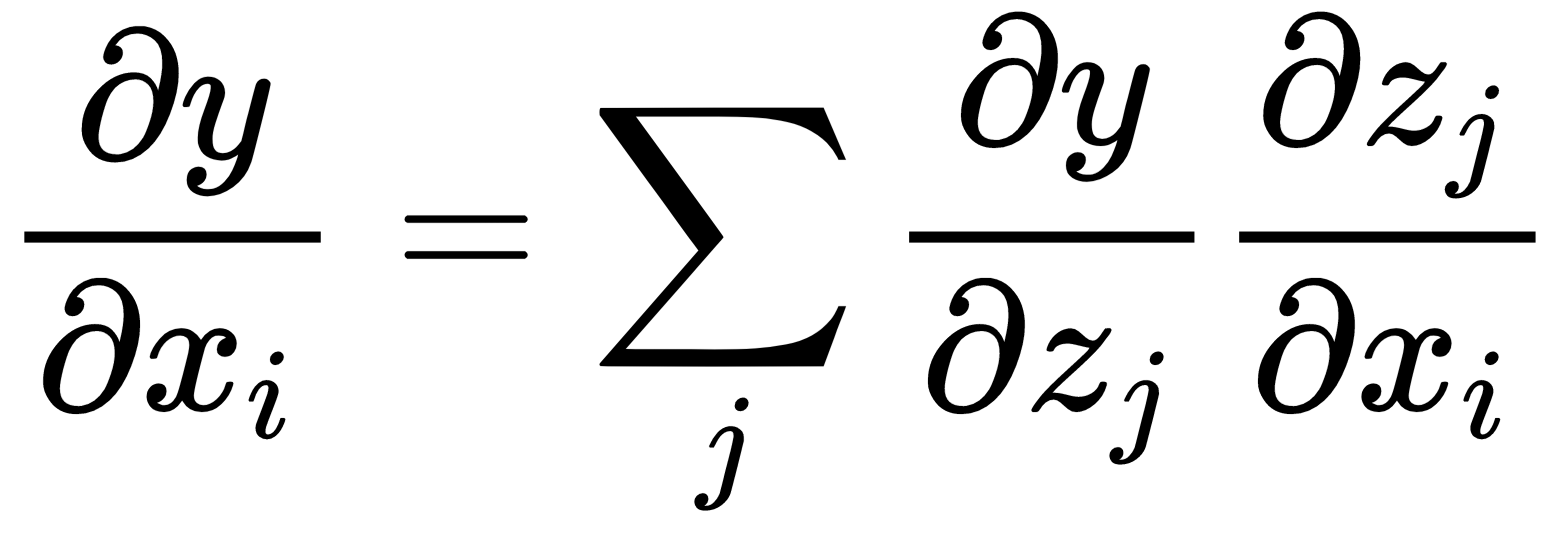
We can express ...