December 2018
Beginner to intermediate
684 pages
21h 9m
English
As we mentioned previously, a policy, π, maps all states to probability distributions over actions so that the probability of choosing action At in state St can be expressed as 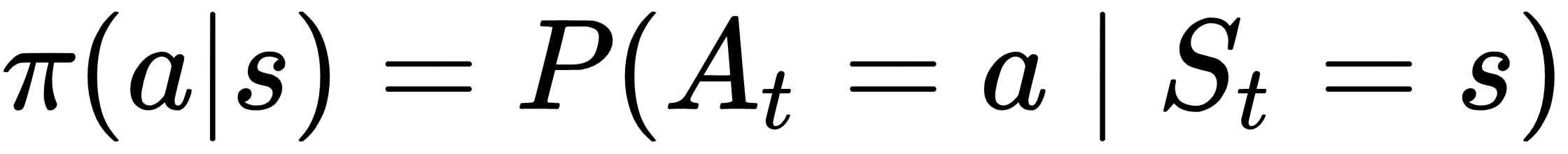 . The value function estimates the long-run return for each state or state-action pair. It is fundamental to find the policy that is the optimal mapping of states to actions.
. The value function estimates the long-run return for each state or state-action pair. It is fundamental to find the policy that is the optimal mapping of states to actions.
The state-value function 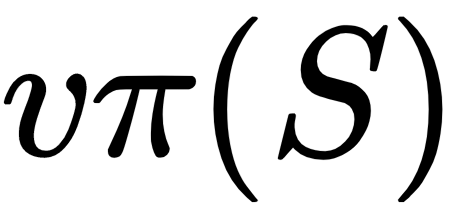 for the π policy gives the long-term value, v, of a state, S as the expected return, G, for an agent that starts in ...
for the π policy gives the long-term value, v, of a state, S as the expected return, G, for an agent that starts in ...