December 2018
Beginner to intermediate
684 pages
21h 9m
English
Preprocessing typically involves phrase detection, that is, the identification of tokens that are commonly used together and should receive a single vector representation (for example, New York City, see the discussion of n-grams in Chapter 13, Working with Text Data).
The original Word2vec authors use a simple lift scoring method that identifies two words wi, wj as a bigram if their joint occurrence exceeds a given threshold relative to each word's individual appearance, corrected by a discount factor δ:
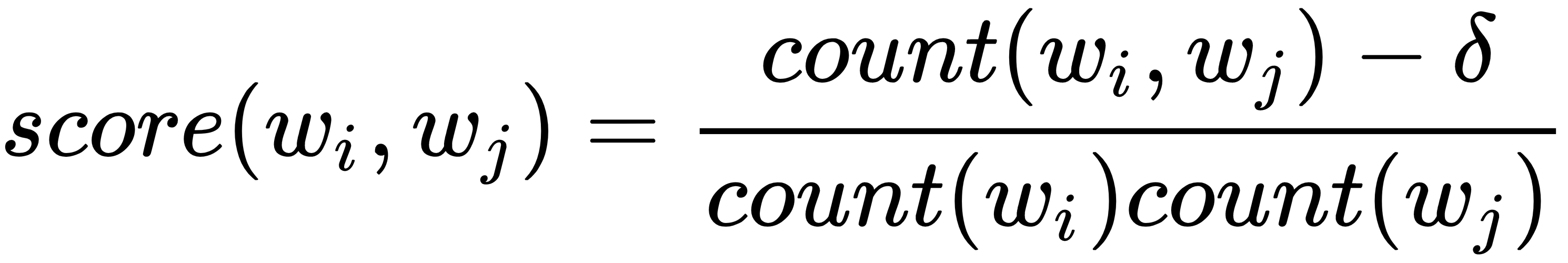
The scorer can be applied repeatedly to identify successively longer phrases.
An alternative is the normalized ...