December 2018
Beginner to intermediate
684 pages
21h 9m
English
Perplexity, when applied to LDA, measures how well the topic-word probability distribution recovered by the model predicts a sample, for example, unseen text documents. It is based on the entropy H(p) of this distribution p and computed with respect to the set of tokens w:
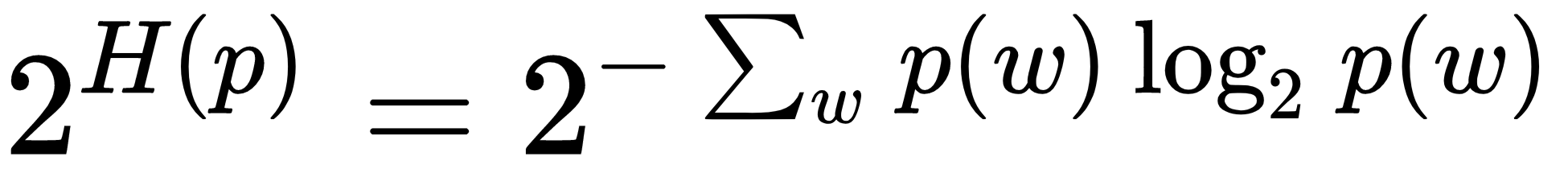
Measures closer to zero imply the distribution is better at predicting the sample.