10.5 クラスタリング 301
10.5 クラスタリング
クラ
スタリングとは、類似性に基づいて点をグループにまとめる問題を指す。要素は少数の論理的な
「ソース」や「説明」を持つことが多い。クラスタリングは、それらを明確にする方法として優れている。異
星人が人類の身長と体重のデータを見るようなことがあれば、何と思うだろうか。おそらく、別々の母集団
を持つ 2 つのクラスタがあるらしいということに気付くだろう。片方がもう片方よりも一貫して大きいので
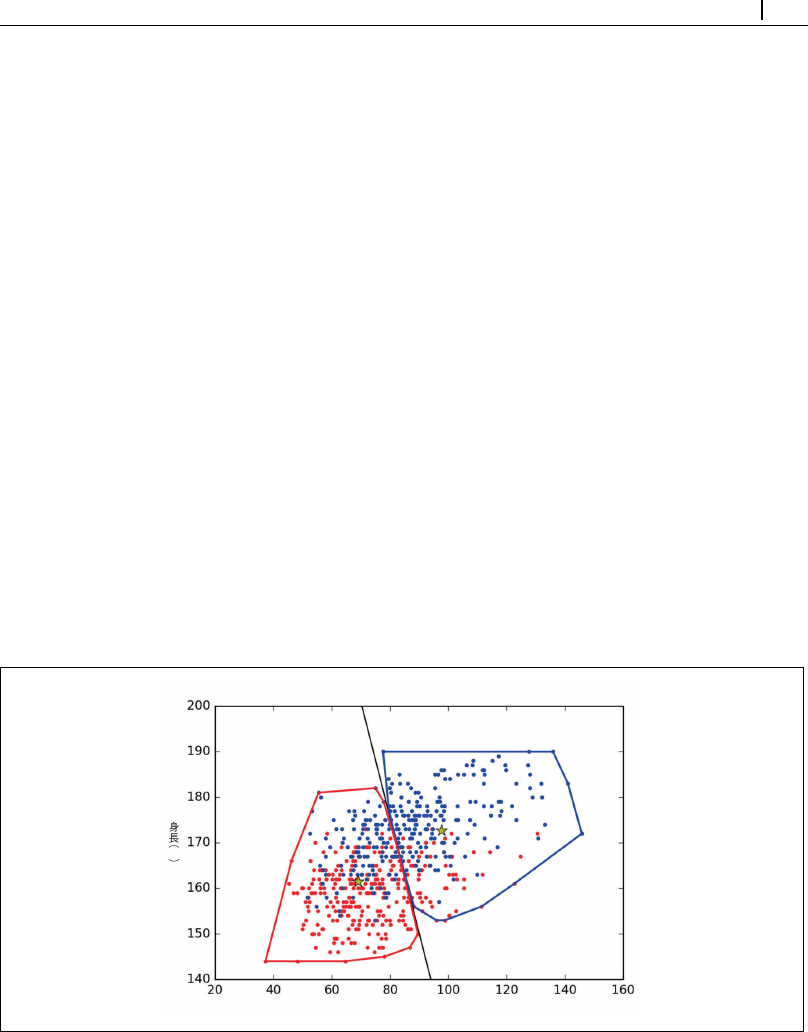
ある。その異星人たちが本当に有能であれば、2 つの母集団を「男性」と「女性」と呼ぶだろう。実際、図
10 -11 の 2 つの身長—体重クラスタはともに、どちらかの性に集中している。
2 次元散布図のパターンは一般にわかりやすいが、我々は人間が可視化できない高次元データを扱うこと
も多い。そのようなときには、我々の代わりにパターンを見つけてくれるアルゴリズムが必要だ。クラスタ
リングは、おそらく面白いデータセットを前にして最初に行うことだろう。クラスタリングの応用として
は、次のようなものが考えられる。
• 仮説設定:(例えば)データセットが 4 種類の母集団からとられたもののように見えるとすれば、す
ぐに、なぜそのようなものができたのかという疑問が生まれる。これらのクラスタが密集しており、
十分離れているなら、何らかの理由があるに違いないし、その理由を明らかにするのはデータサイエ
ンティストの仕事だ。個々の要素にクラスタラベルを付けたら、同じクラスタに属する代表的なデー ...






