248
4
章
Matplotlib
による可視化
4.7
ヒストグラム、ビニング、密度
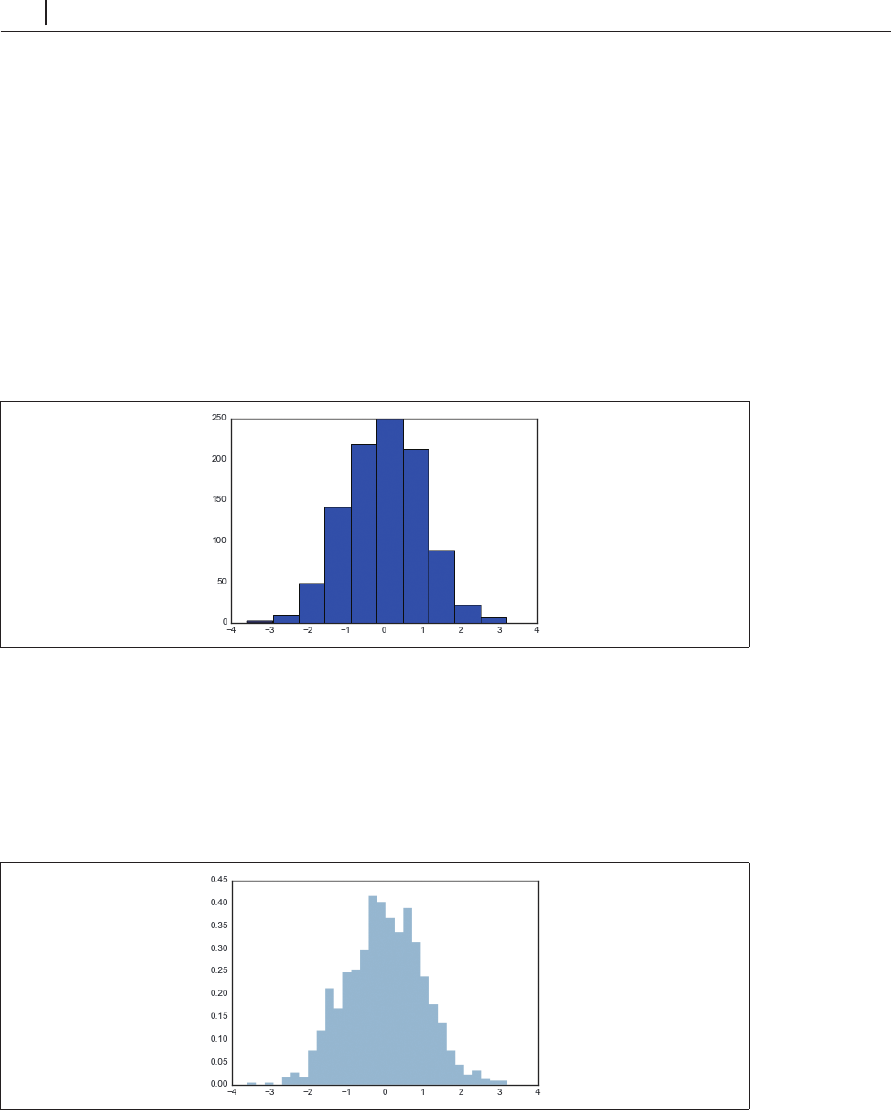
簡単なヒストグラムは、データセットを理解するための最初の重要なステップです。既に、
Matplotlib
のヒストグラム関数は紹介済みです(「2.6 比較、マスク、ブール論理」を参照)。これは、
定型のインポートを別にして、基本的なヒストグラムを
1
行で作成できます(図 4-35)。
In[1]: %matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('seaborn-white')
data = np.random.randn(1000)
In[2]: plt.hist(data);
図4-35 単純なヒストグラム
hist()
関数には、計算と表示の両方を調整するためのオプションが数多く用意されています。
よりカスタマイズされたヒストグラムの例を次に示します(図 4-36)。
In[3]: plt.hist(data, bins=30, normed=True, alpha=0.5,
histtype='stepfilled', color='steelblue',
edgecolor='none');
図4-36 カスタマイズされたヒストグラム