5.8
詳細:決定木とランダムフォレスト
429
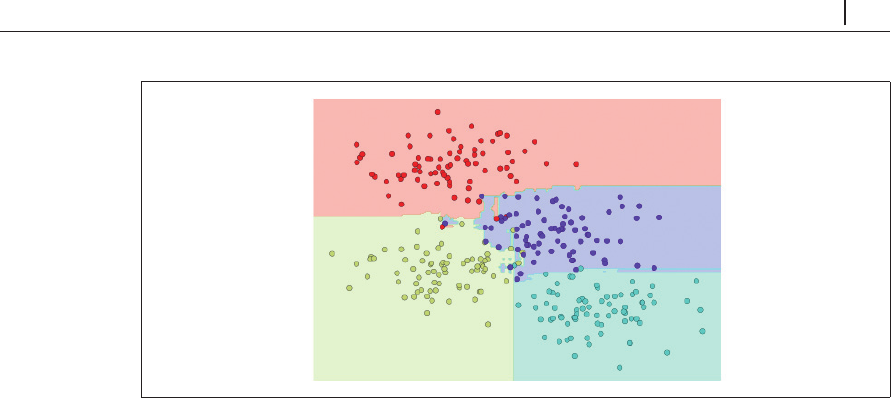
図5-75 決定木の最適化されたアンサンブルであるランダムフォレストによる境界検出
ランダムに摂動させた
100
以上のモデルを平均化することで、全体的に直感に近いパラメータ空
間の分割モデルとなります。
5.8.3
ランダムフォレスト回帰
前の節では、ランダムフォレストを分類に使用しました。ランダムフォレストは回帰(すなわち、
カテゴリ変数ではなく連続量)にも使えます。推定器は
RandomForestRegressor
を使用します。構
文は
RandomForestClassifier
と非常によく似ています。
細かいサイクルと大きなサイクルを組み合わせた次のデータで考えてみましょう(図 5-76)。
In[10]: rng = np.random.RandomState(42)
x = 10 * rng.rand(200)
def model(x, sigma=0.3):
fast_oscillation = np.sin(5 * x)
slow_oscillation = np.sin(0.5 * x)
noise = sigma * rng.randn(len(x))
return slow_oscillation + fast_oscillation + noise
y = model(x)
plt.errorbar(x, y, 0.3, fmt='o');