354
5
章 機械学習
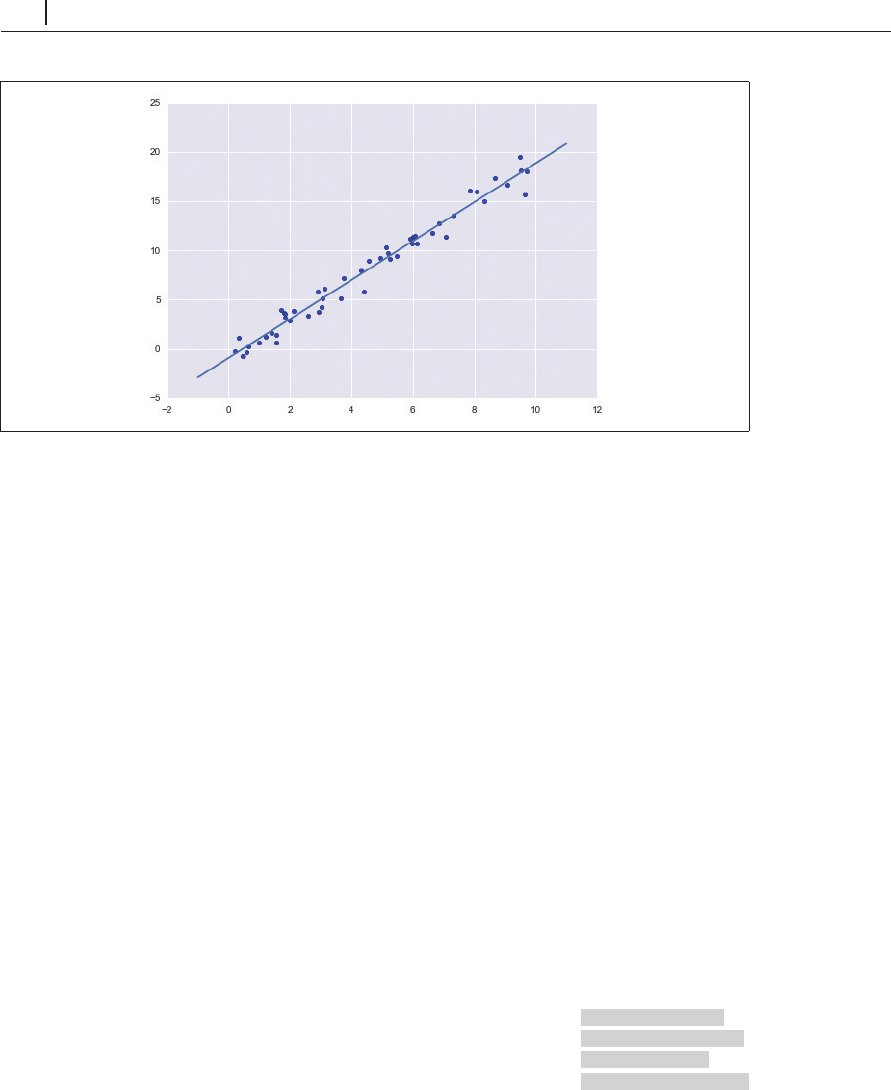
図5-15 データへの単回帰当てはめ
5.2.2.3
教師あり学習の事例:アイリスの分類
既出のアイリスデータセットを使用して、この手順の別の例を見てみましょう。次の問いを考え
ます。アイリスデータの一部で訓練したモデルは、残りのデータのラベルをどの程度正しく予測で
きるでしょうか。
このタスクでは、ガウシアンナイーブベイズ(
Gaussian naive Bayes
)と呼ばれる非常に簡単な生
成モデルを使用します。これは、各クラスが軸ごとにガウス分布を持つと仮定して処理を行います。
(詳細は、「5.5 詳細:ナイーブベイズ分類」を参照)
。ガウシアンナイーブベイズは、非常に高速
で、選択すべきハイパーパラメータを持たないため、より洗練されたモデルで改善が見られるかど
うかを調べる前に、基準となる分類として使用するのに適したモデルです。
学習時のデータとは異なるデータを使ってモデルを評価したいので、データを学習
セットとテス
トセットに分割します。これは手作業で行ってもよいのですが、
train_test_split
ユーティリティ
関数を使用する方が簡単です。
In[15]: from sklearn.model_selection import train_test_split
Xtrain, Xtest, ytrain, ytest = train_test_split(X_iris, y_iris,
random_state=1)
データを分けた後、手順に沿って予測を行います。
In[16]: ...