82
2
章
NumPy
の基礎
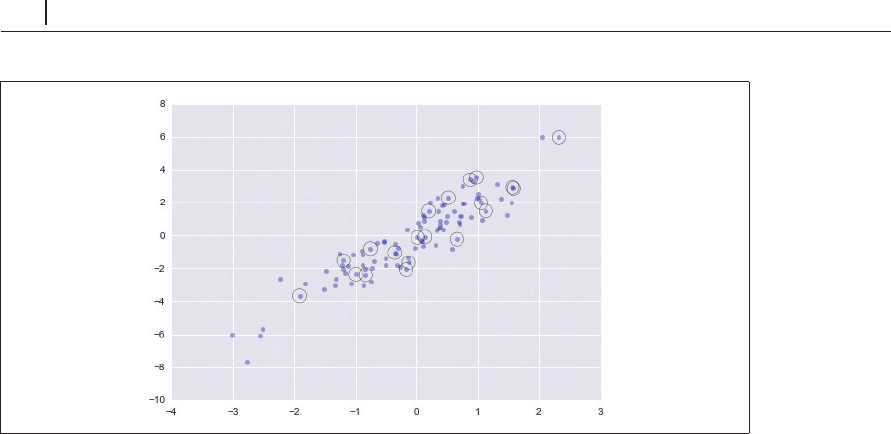
図2-8 ポイントのランダムな選択
統計モデルの検証を行う際のトレーニング
/
テスト分割(「5.3 ハイパーパラメータとモデルの
検証」を参照)や、統計的な質問に回答するためのサンプリングで必要とされるように、こうした
手法はデータセットを簡単に分割するために使われます。
2.7.4
ファンシーインデクスを使った値の変更
ファンシーインデクスは配列の一部にアクセスするために使用できるように、配列の一部を変更
するためにも使用できます。例えば、インデクスの配列があるとして、そのインデクスの要素をあ
る値に設定したいとします。
In[18]: x = np.arange(10)
i = np.array([2, 1, 8, 4])
x[i] = 99
print(x)
[ 0 99 99 3 99 5 6 7 99 9]
この操作では、任意の代入式演算子を使用できます。例を示しましょう。
In[19]: x[i] -= 10
print(x)
[ 0 89 89 3 89 5 6 7 89 9]
ただし、これらの操作でインデクスが繰り返し指定されると、予期しない結果が生じる可能性が
あることに注意してください。次の点を考慮する必要があります。
In[20]: x = np.zeros(10)
x[[0, 0]] = [4, 6]
print(x)