408
5
章 機械学習
In[1]: %matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
# use Seaborn plotting defaults
デフォルトで
seaborn
を使用する
import seaborn as sns; sns.set()
5.7.1
サポートベクターマシンの必要性
ベイズ分類(「5.5 詳細:ナイーブベイズ分類」を参照)を取り上げた際に、各クラスの分布を表
す簡単なモデルを基にした生成モデル(
generative model
)を使用して、新しいポイントのラベルを
確率的に求めました。それは生成分類の一例でしたが、ここでは識別分類で各クラスをモデリング
するのではなく、単純にクラスを分割する直
線や曲線(
2
次元の場合)または多様体(多次元の場合)
を見つけます。
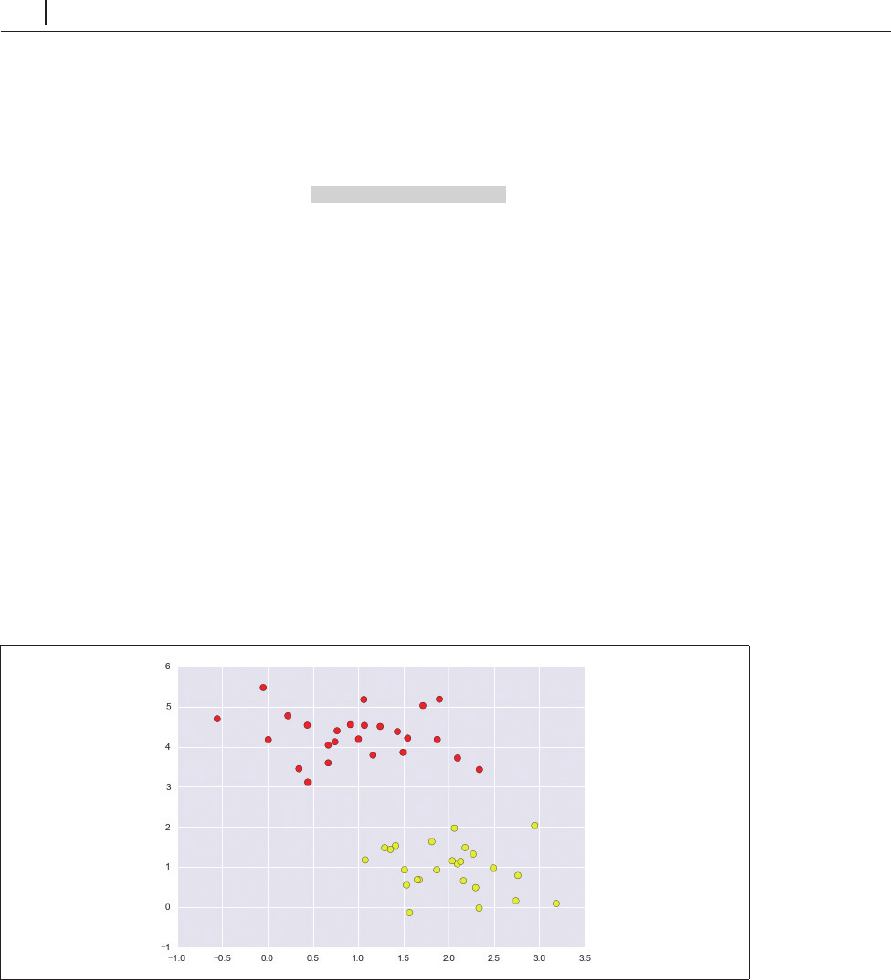
一例として、
2
つのクラスが明確に分かれている場合の、単純な分類について考えてみましょう
(図5-53)。
In[2]: from sklearn.datasets.samples_generator import make_blobs
X, y = make_blobs(n_samples=50, centers=2,
random_state=0, cluster_std=0.60)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn'); ...