5.1
機械学習とは?
337
5.1.2
定性的な機械学習アプリケーションの例
こうした考え方をより具体的にするために、機械学習タスクの非常に簡単な例をいくつか
見てみましょう。これらの例は、本章で取り上げる機械学習手法を直感的かつ非定量的に概
観することを目的としています。特定のモデルとその使用方法については、後の節で詳しく
説明し ます。 技術 的な 側面 につ いて は、オ ンライン の
Appendix
(
https://github.com/jakevdp/
PythonDataScienceHandbook
)で提供した、図を生成する
Python
ソースを使って確認してください。
5.1.2.1
分類:離散ラベルの予測
ラベル付けされたデータポイントの集合が与えられたとして、これを使ってラベルが付いていな
いデータポイントを分類するという単純な分類タスクを見てみます。
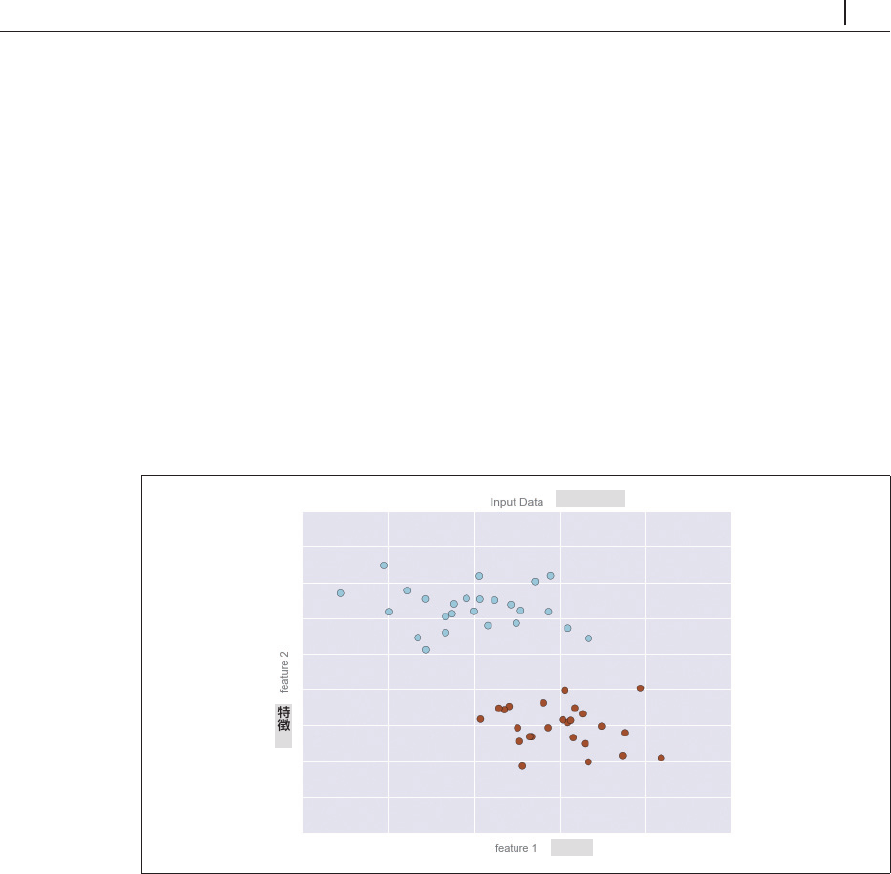
図5-1に示すデータがあるとします(この図だけでなく、この
節のすべての図を生成するコード
は、オンラインの
Appendix
から入手できます)。
入力データ
特徴
1
2
図5-1 分類のための単純なデータセット
これは
2
次元データなので、各点は平面上の
(
x
,
y
)
位置によって表される
2
つの特徴を有します。
さらに、各点には
2
値のクラスラベルが割り当てられ、ここでは点の色で表されています。これら
の特徴やラベルから、新しい点が与えられた場合に「青」または「赤」どちらのラベルを付けるかを
決定するモデルを作成します。
このような分類を行うモデルはいくつも考えられますが、ここでは非常に単純なものを使用しま ...